Dedupe.io was shut down Jan 31, 2023.
The Dedupe.io team has decided to dedicate our focus to our consulting practice at DataMade and work on projects more aligned with our mission to support our clients in working toward democracy, justice, and equity.
We are continuing our consulting practice around the open source dedupe library and would be happy to consult with you on setting up a solution based on it. Contact us to get started >
Dedupe.io is a software as a service platform for quickly and accurately identifying clusters of similar records across one or more files or databases. In this tutorial, we will go over how to de-duplicate your first dataset using Dedupe.io.
You can watch this tutorial as a video, or follow along with it playing in another window.
For datasets smaller than 100,000 records, it should take less than 30 minutes for you to walk your data through the Dedupe.io wizard. Larger datasets will take longer. Keep an eye out in this tutorial for tips and tricks to reduce the amount of time and effort and how to achieve the best results.
Size limitations
The size of the spreadsheet you can upload depends on your account limit, which you can view on the My account page. If the spreadsheet has more rows than are allowed for your account, you can contact us at info@datamade.us to upgrade your plan.
Dedupe.io has a hard limit of 500mb for uploading files. For larger datasets, contact us at info@datamade.us.
Pre-processing your data
If your spreadsheet contains more than one header row, columns with duplicate names, or columns with no field name, you will need to edit your file to correct these issues before uploading.
Once you upload your data to Dedupe.io, you will not be able to edit it. We take the approach of dealing with data in its original messy state and simply identify which records to cluster together.
However, there are some cases where editing your data before uploading to Dedupe.io is a good idea. If a column has a lot of blank values, that’s ok. Dedupe.io will know how to ignore them appropriately. However, if your data has text like “Null” or “n/a” in them, it would be a good idea to clear them out. We recommend using tools like Excel, or Open Refine for larger spreadsheets to make these kinds of changes.
If you don’t have a file suitable for de-duplicating, you can use our example spreadsheet of early childhood education centers in Chicago:
Download Chicago Early Childhood Locations (800 rows)Ready? Let’s get started!
Once you have an account and are logged in at app.dedupe.io, click the ‘Upload a new dataset’ button. You’ll be taken to the ‘Upload data’ page.
Here, you can name your dataset, provide and optional description for it. You will also be prompted to Create a new project or Add to an existing project.
Projects are used for grouping multiple datasets together for matching (See our merging and matching tutorial). We won’t be doing that now, so you can just select Create a new project and add a Project name and Project description.
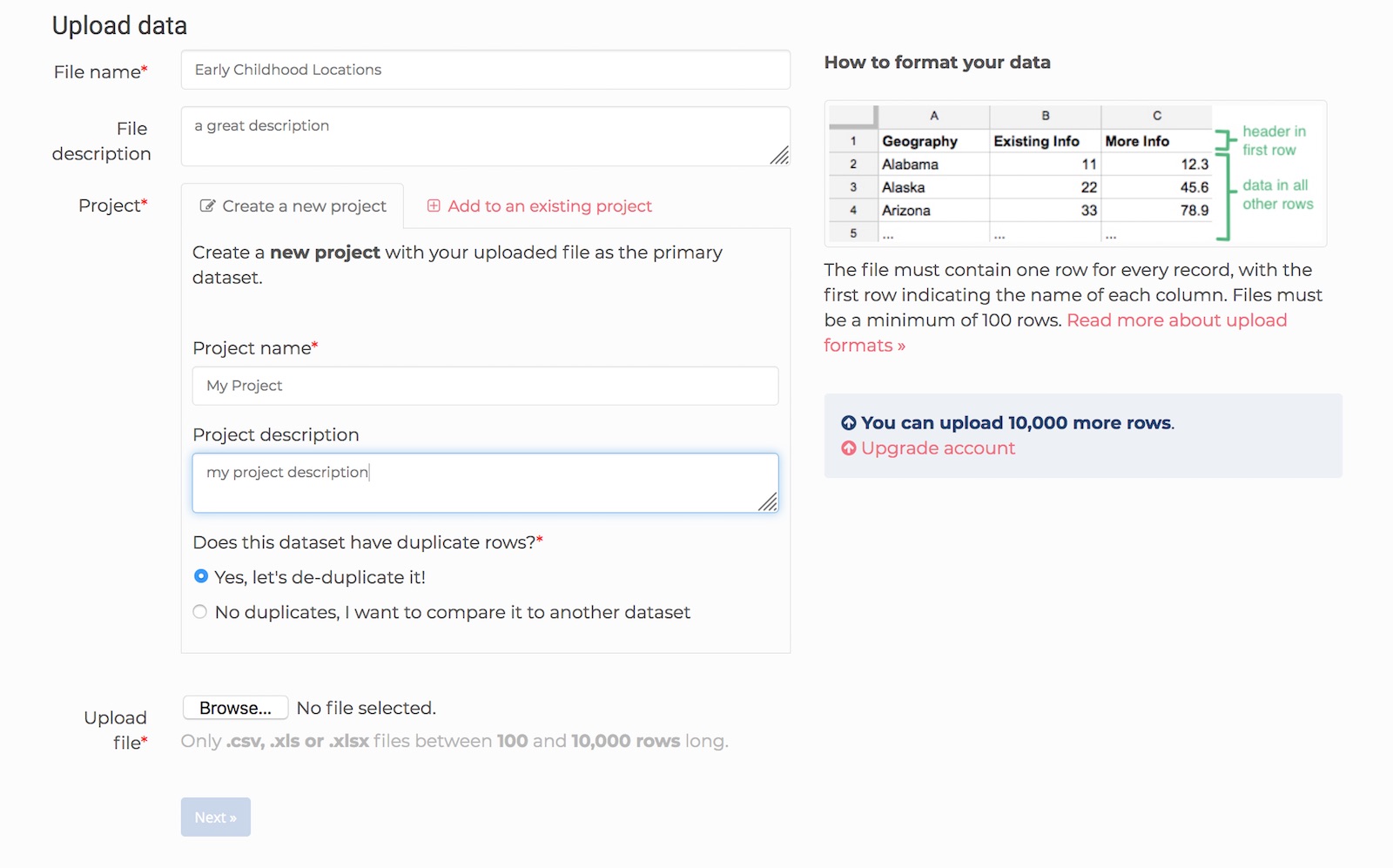
The 'Upload data' page on Dedupe.io
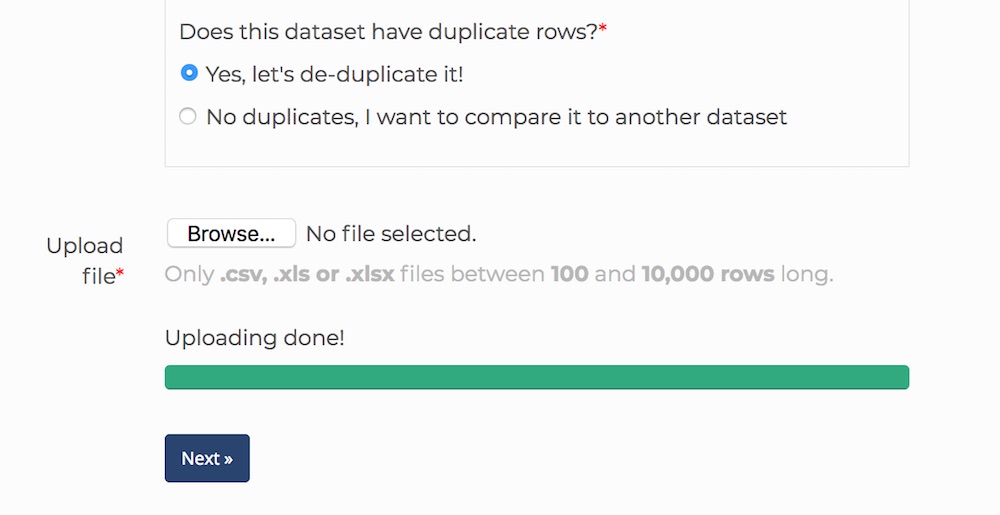
You can keep Yes, let’s de-duplicate it! selected for now. We cover this feature in our merging and matching multiple datasets tutorial.
The last step is to upload your data. Dedupe.io accepts Excel spreadsheets (XLS or XLSX), or comma separated values (CSV) files. The file must contain one row for every record, with the first row indicating the name of each column.
Pick a file from your computer and wait for it to finish uploading. When it’s done, you’ll be shown the ‘Next’ button.
Next, we will identify the fields, or columns, that we want Dedupe.io to pay attention to for finding duplicates. You’ll be shown a drop down list of column names to pick from.
Next to that, you will pick from Compare as to tell Dedupe.io how to compare values in that column. The Default comparator will compare based on how similar each field is, character by character. Address will automatically split addresses into separate components to facilitate comparison (so that city gets compared to city, etc). Name will do the same for person and company names.
Dedupe.io has several other kinds of comparators, which you can read about on the field comparator page.
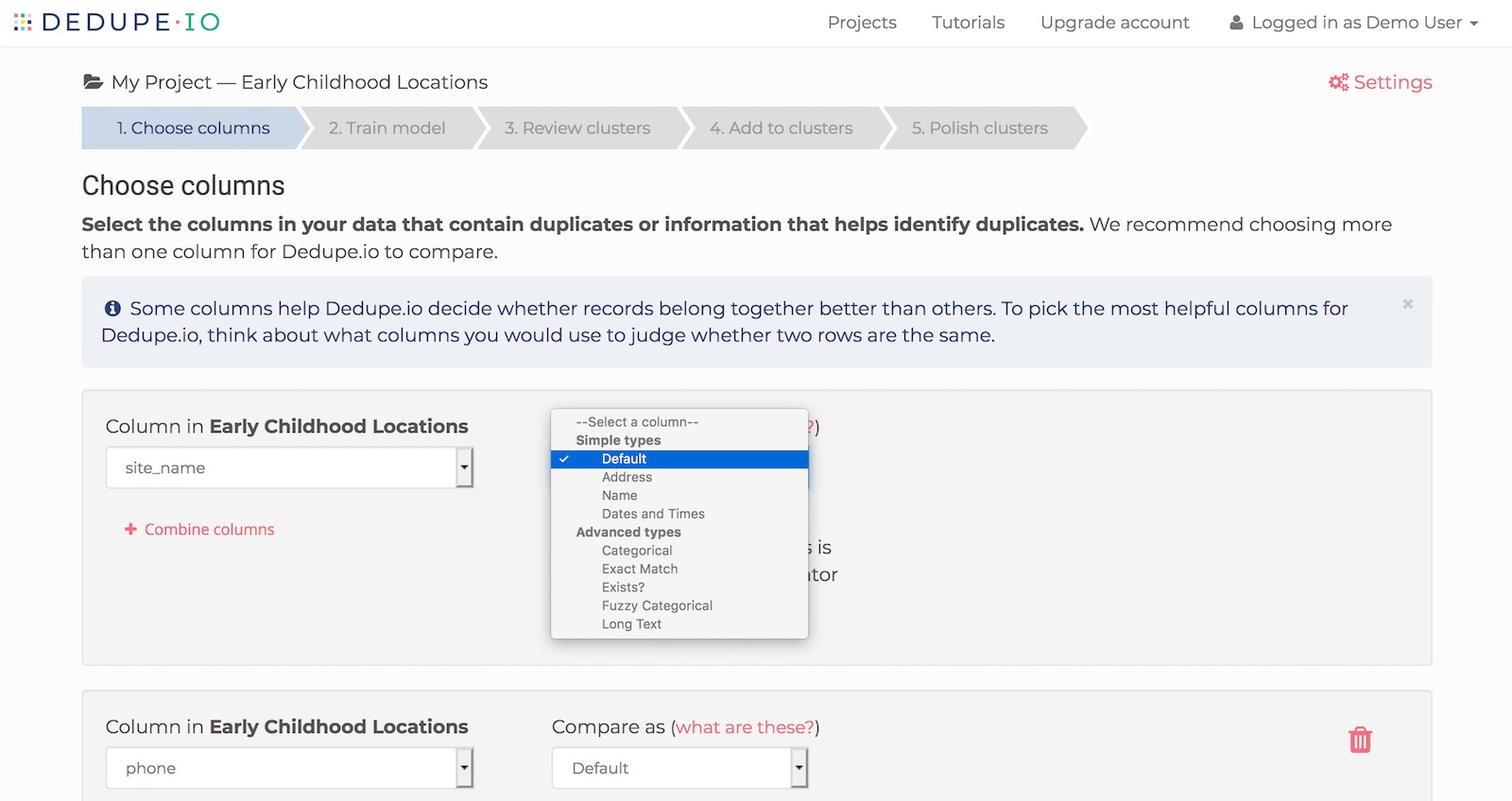
Don’t stop with just one field, though! Dedupe.io can compare multiple fields, which is what we recommend whenever possible. Add additional fields by clicking the blue ‘Add field to compare’ button in the lower right corner.
Combining fields
Sometimes information you want to compare are spread across multiple columns. This happens often with address fields being split up into columns like address, city, state and zip code. We’ve found that for the best results, it’s best to combine these fields to one and compare them together.
In this example, we’ve combined the ‘address’ and ‘zip’ columns together and are using the Address comparator.
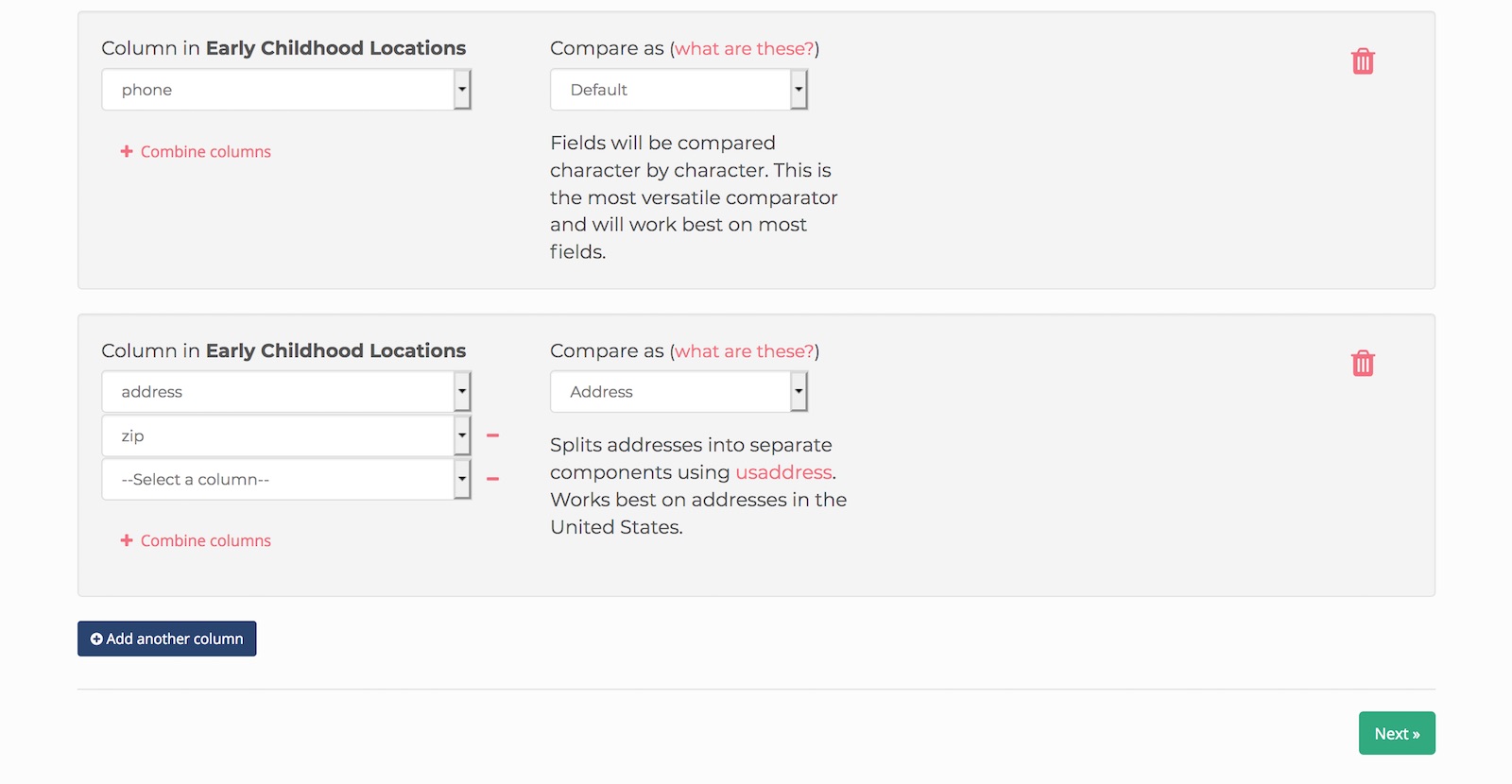
Picking the right columns
The basic rule of thumb for picking fields to compare is: if you looked at two records, what information would you use to identify if they are the same or not? Fields like name, address, phone number and category are the most useful, but it could be anything.
The more fields you can tell Dedupe.io to look at that has useful information for comparisons, the better.
Once you’ve picked your columns and click the ‘Next’ button, Dedupe.io will take a moment to process your data. It will automatically find and cluster records that are exact matches. Then, it will take a sample of the remaining records and pick two random ones for you to review.
Here, we are shown two records that are clearly referring to the same place, but have some slight variations in their name and address:
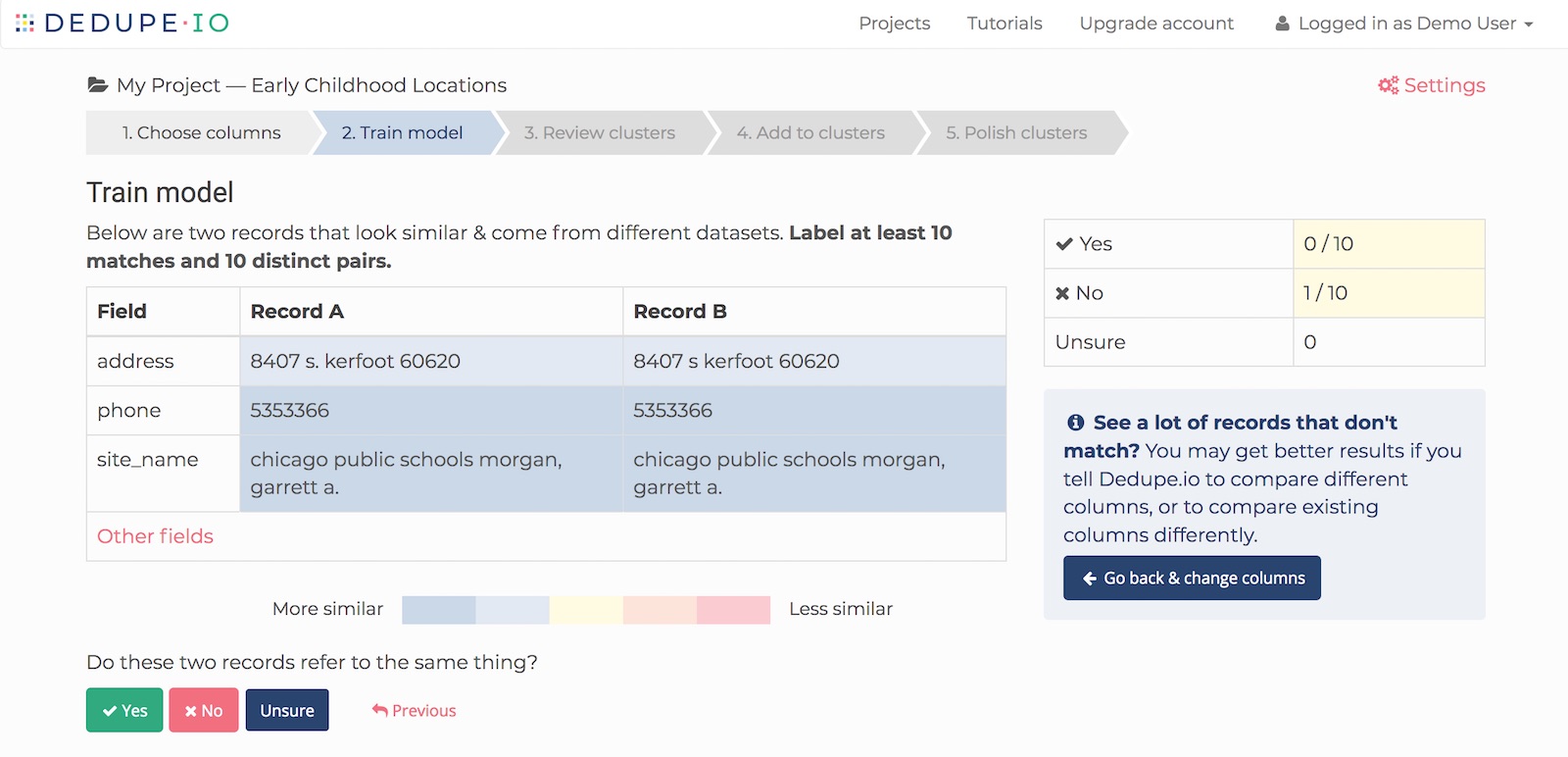
For this pair of records, Dedupe.io asks us, ‘Do these records refer to the same thing?’ We will answer ‘Yes’, ‘No’, or ‘Unsure’. Once we mark these records, Dedupe.io will find another pair for us to review and we’ll repeat the process.
Here’s a pair of records that look like they don’t match:
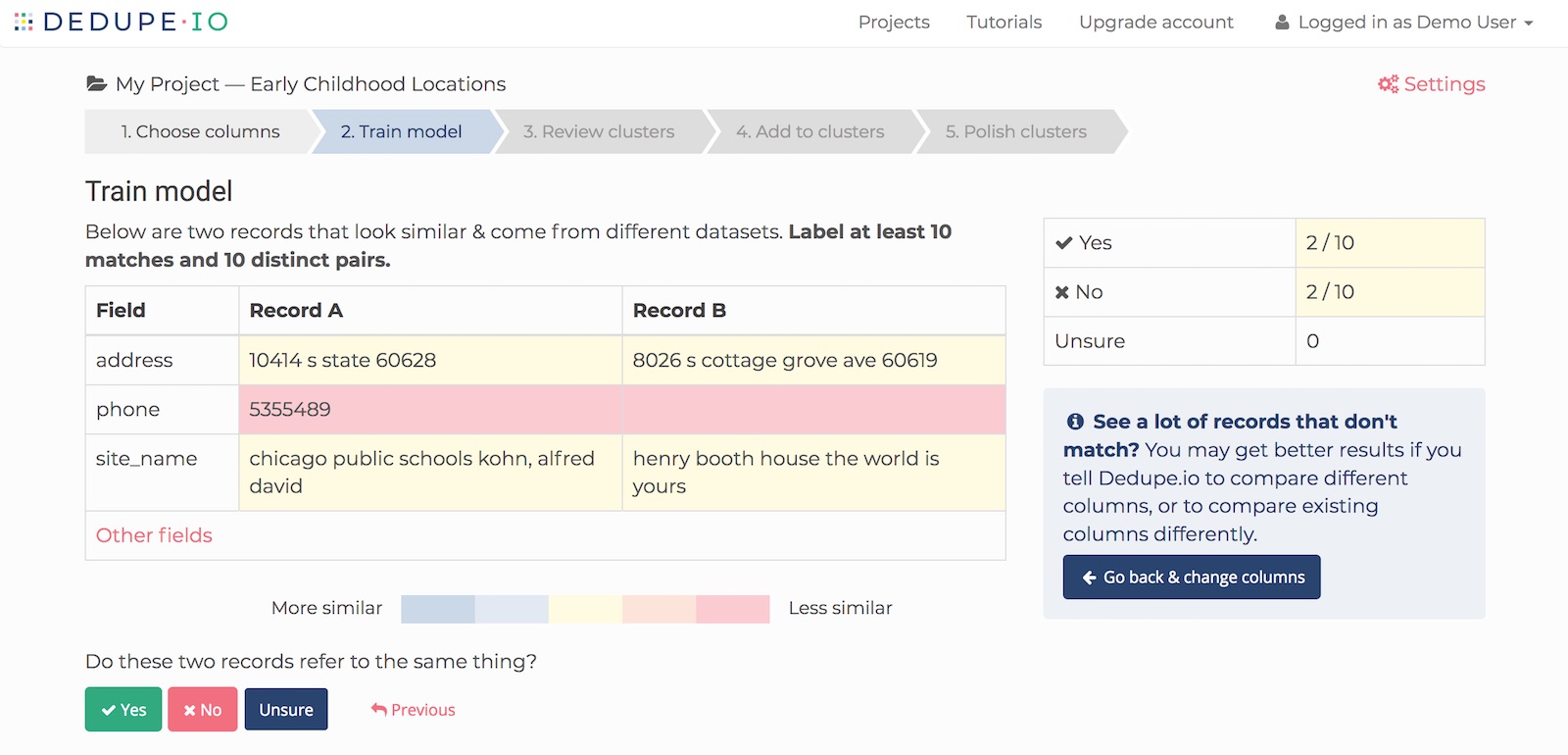
Dedupe.io uses these responses to refine its understanding of your data. The more training you provide, the better the de-duplication results will be. At a minimum, we need 10 positive and 10 negative responses to proceed.
You are, however, welcome to provide as much training as you’d like. Just know that Dedupe.io will learn a little less for each additional training pair you mark. Stopping at 50 yes and 50 no responses would be more than enough for most datasets.
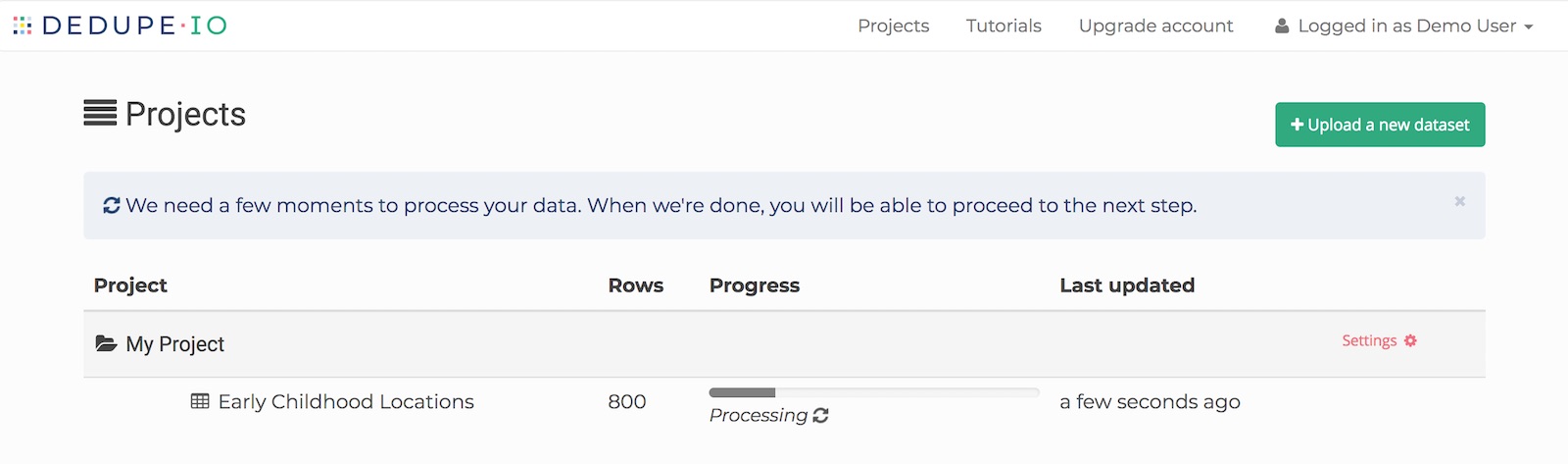
Once you’re done training and click the ‘Next’ button, Dedupe.io will take some time to apply your training to the rest of your data. This can take several minutes for datasets under 100,000 rows to several hours for datasets with millions of rows.
While it’s processing, it will show you a message:
When it’s finished processing, you’ll be able to continue your task:
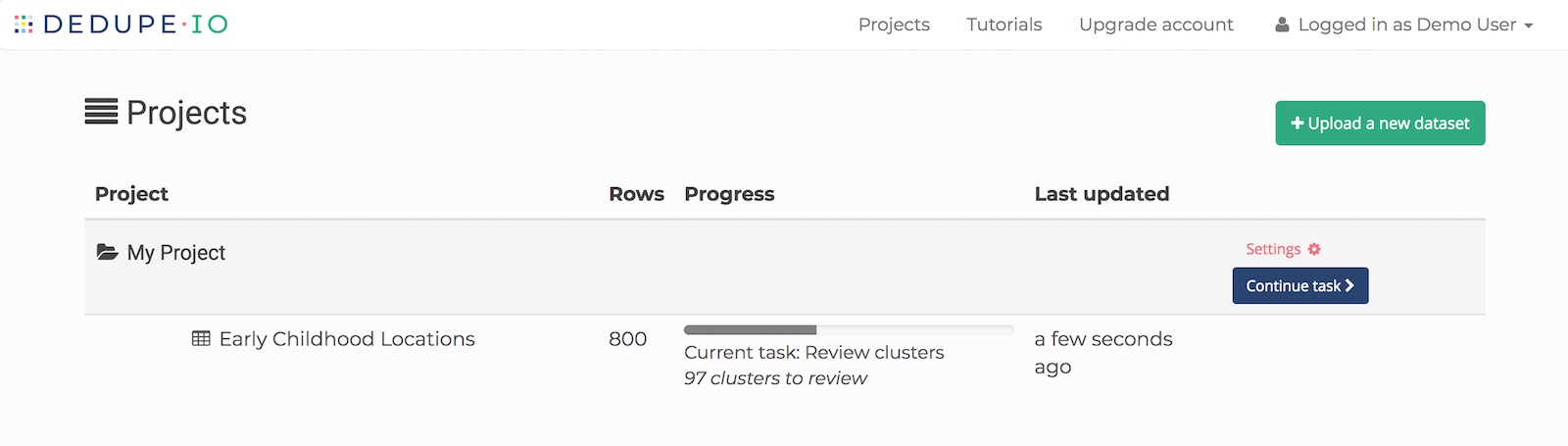
When you do, you’ll be shown a collection of records which Dedupe.io has identified as a cluster. Next to each record is a checkbox to indicate if the record should be included in the cluster.
Here’s an example of a cluster of four records, all with the same phone number, but slight variations in address formatting and length of name. They are all the same, so we will keep them all checked and click ‘Save cluster’.
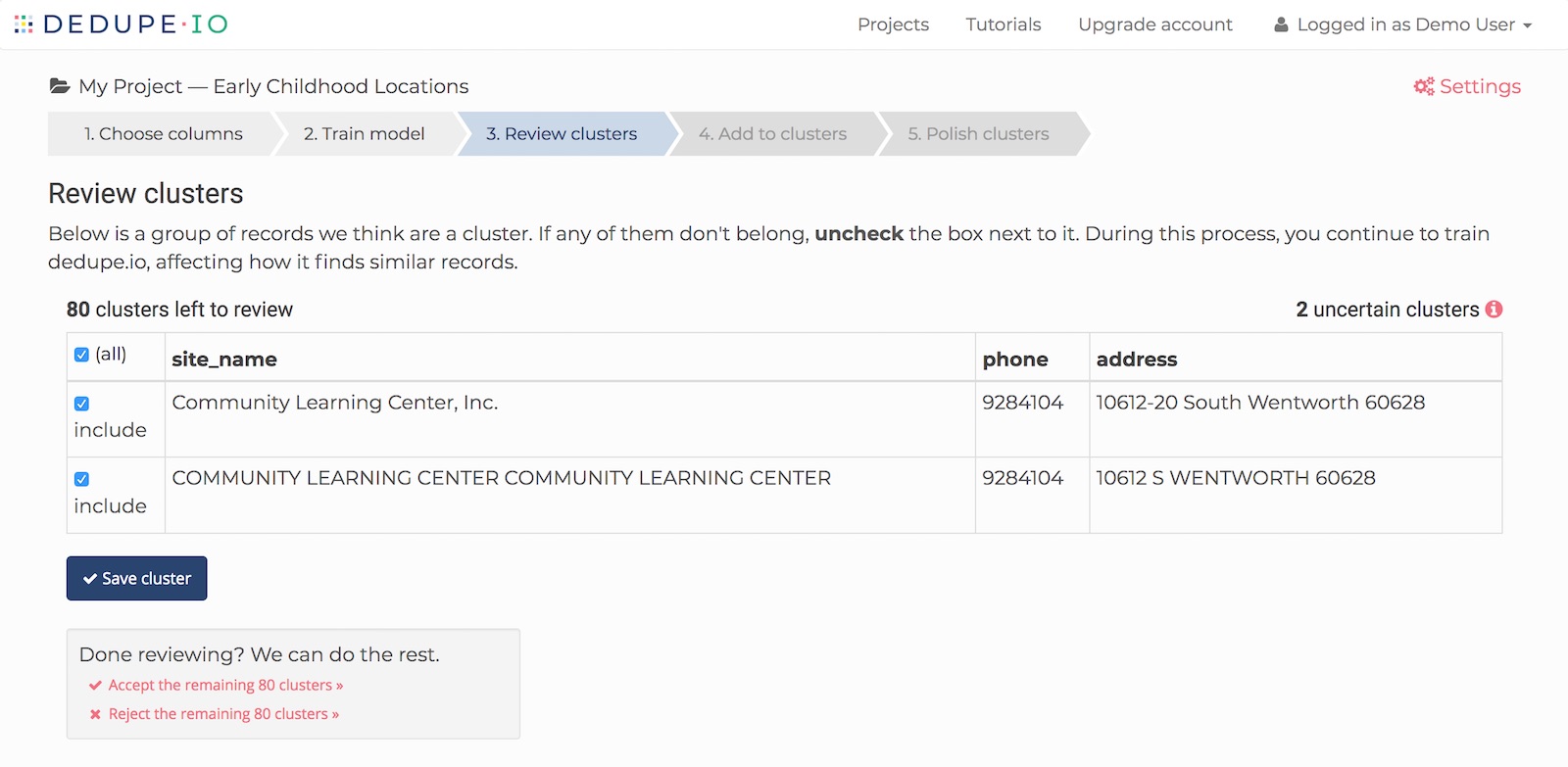
If a record does not belong in this cluster, you can uncheck the box next to it. Dedupe.io will remove it from the cluster.
You’ll notice that in this example, there are 751 clusters left to review. This is, excluding the exact duplicates that have already been found, the number of clusters of records dedupe has found so far.
Automatically accepting the rest
If you wanted to review all of them, you can cycle through each one individually and merge or split them apart as needed. But most of us don’t have that much time! You’ll notice in the upper right, that there are 375 uncertain clusters. This is an estimate, based on what Dedupe.io knows so far, on how many records it’s still not confident about being correct.
As you review more records, that number will go down, often dramatically as Dedupe.io gains more confidence. After a while, the number will approach 0. At that point, you are safe to click the ‘Accept the remaining X clusters’ link at the bottom. This will automatically accept the rest of your clusters and skip you to the next step. The reject button will do the same, but will split all the remaining clusters up.
When you’ve finished reviewing your clusters, Dedupe.io will spend some more time processing your data. Now that it has a good idea of the clusters that are in your data, it is looking through all the individual records that have not yet been added to a cluster.
When it is finished, you will be able to continue on to the next step. Here, we will review these records and match them to one or more clusters.
In this example, we have an unmatched record in yellow and a cluster that looks like a good match. We’ll keep the checkbox next to the cluster checked and click the ‘Match record to cluster(s)’ button.
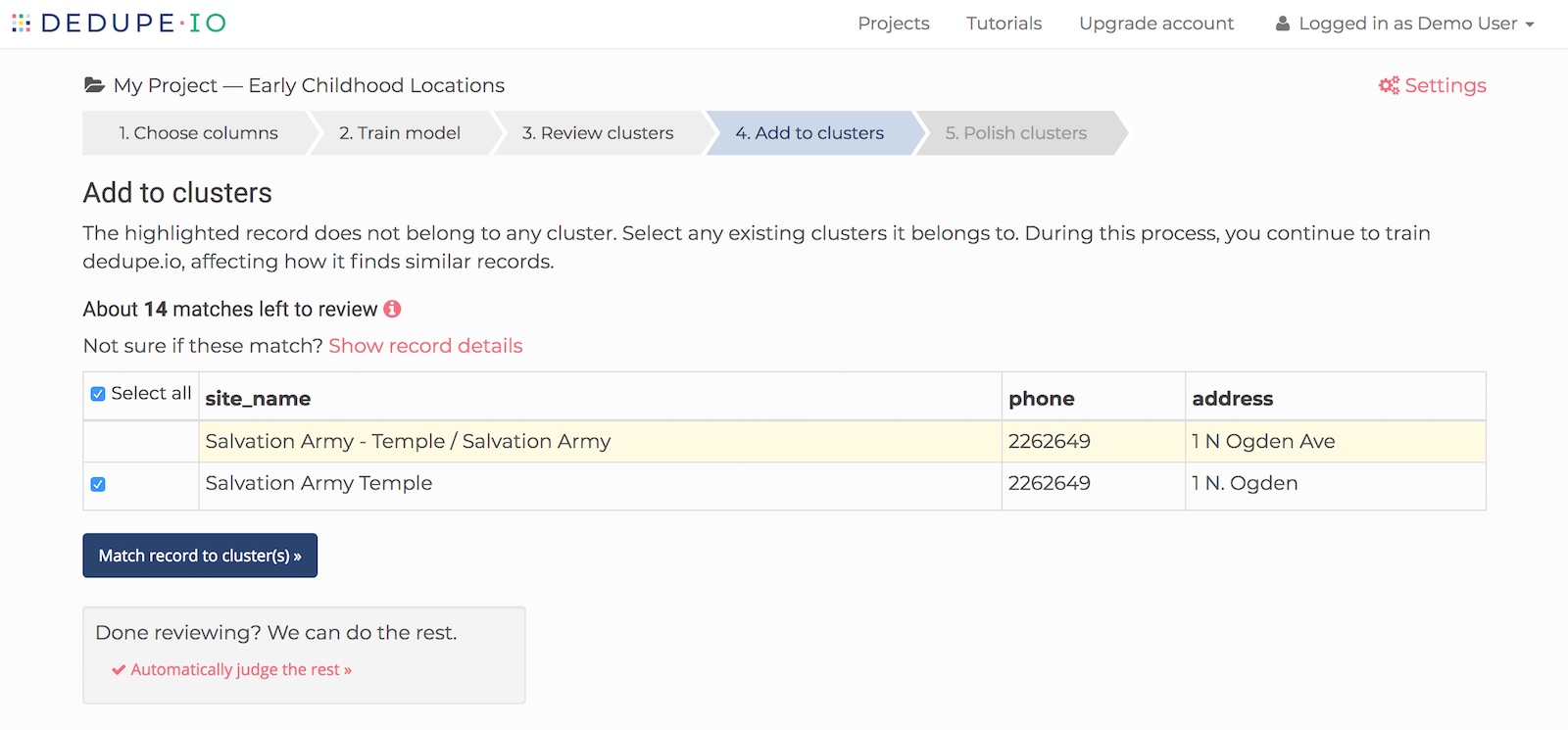
Dedupe.io shows an estimate of the number of matches left for you to review. This is an estimate that will go down as you review more records and the system learns more about your data.
Matching to multiple clusters
In some cases, you will be shown more than one potential cluster to match to. When this happens you can pick one or more cluster to add to. If you match to more than one cluster, Dedupe.io will merge them all into one cluster.
Automatically accepting the rest
Like in the previous step, after reviewing a record, we’ll be shown another one until we’ve gone through the entire queue. Also, like in the previous step, we have the option if we’re confident enough, to ‘Automatically judge the rest’. Clicking this will have Dedupe.io judge the rest of the records automatically and skip us ahead to the next and final step.
Warning: take caution when automatically judging too many records. The records Dedupe.io is asking you to match here are the records that are often the most ambiguous. We recommend reviewing as many of these records as possible for the best results.
Using multiple reviewers In some cases, especially with very large datasets with over 100,000 records, this matching queue will be very long. We recommend reviewing as many of these records as possible for the best results.
To help with this task, we have engineered Dedupe.io to support multiple user accounts working on a dataset at the same time. Contact us at info@datamade.us to set up additional users for your account.
When you’re done adding to clusters, Dedupe.io will process your data again. This time, it is looking for potential clusters to merge. When it’s ready for you to continue your task, you’ll be shown a list of one or more clusters to merge together.
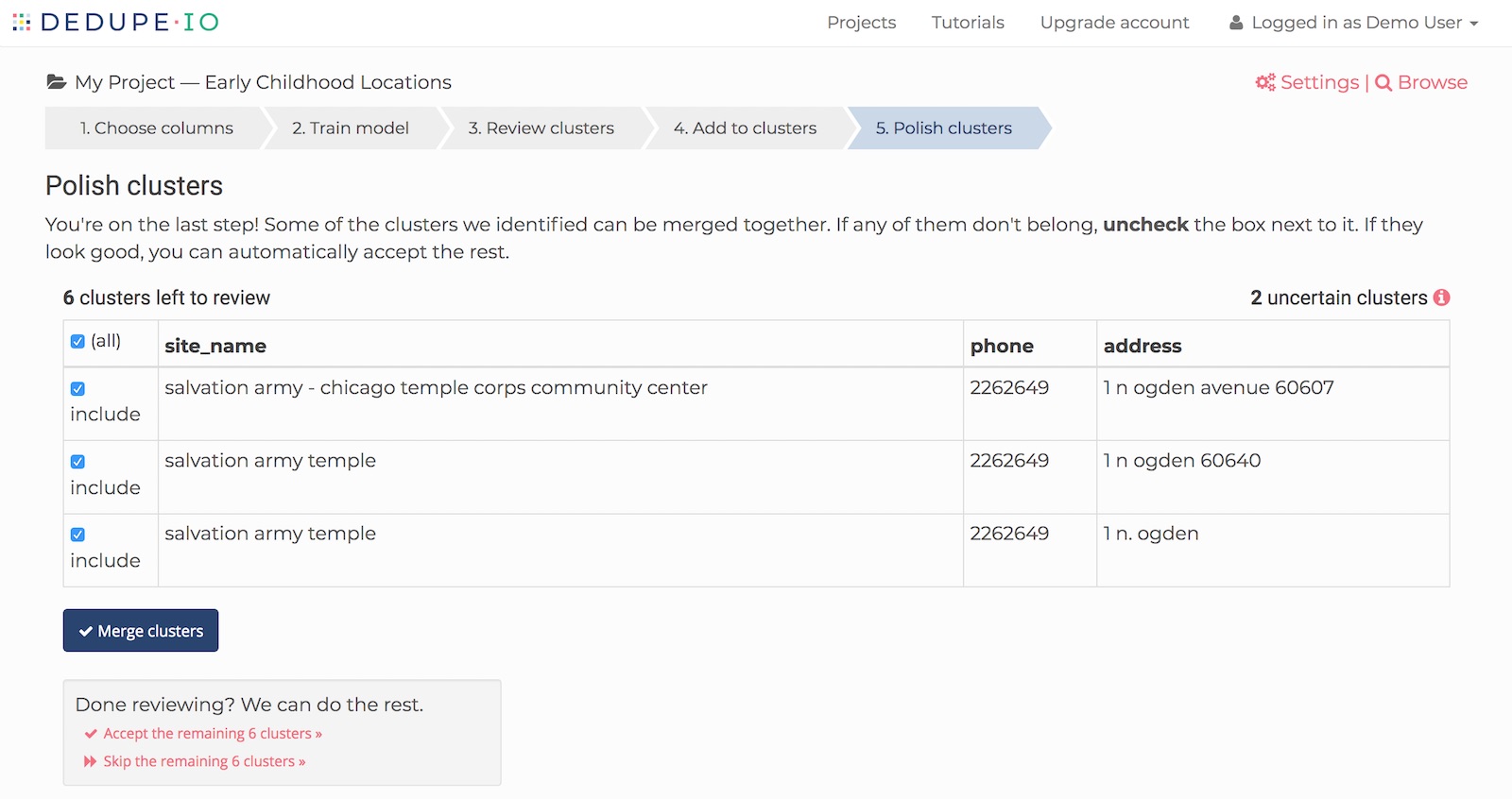
Each row represents an entire cluster of records. Select the clusters to include and click ‘Merge clusters’ if you want to combine them. You will have the option to review all of them, or automatically accept or reject the rest.
Once you’ve reviewed these clusters, Dedupe.io will process your data one final time and you’ll be done!
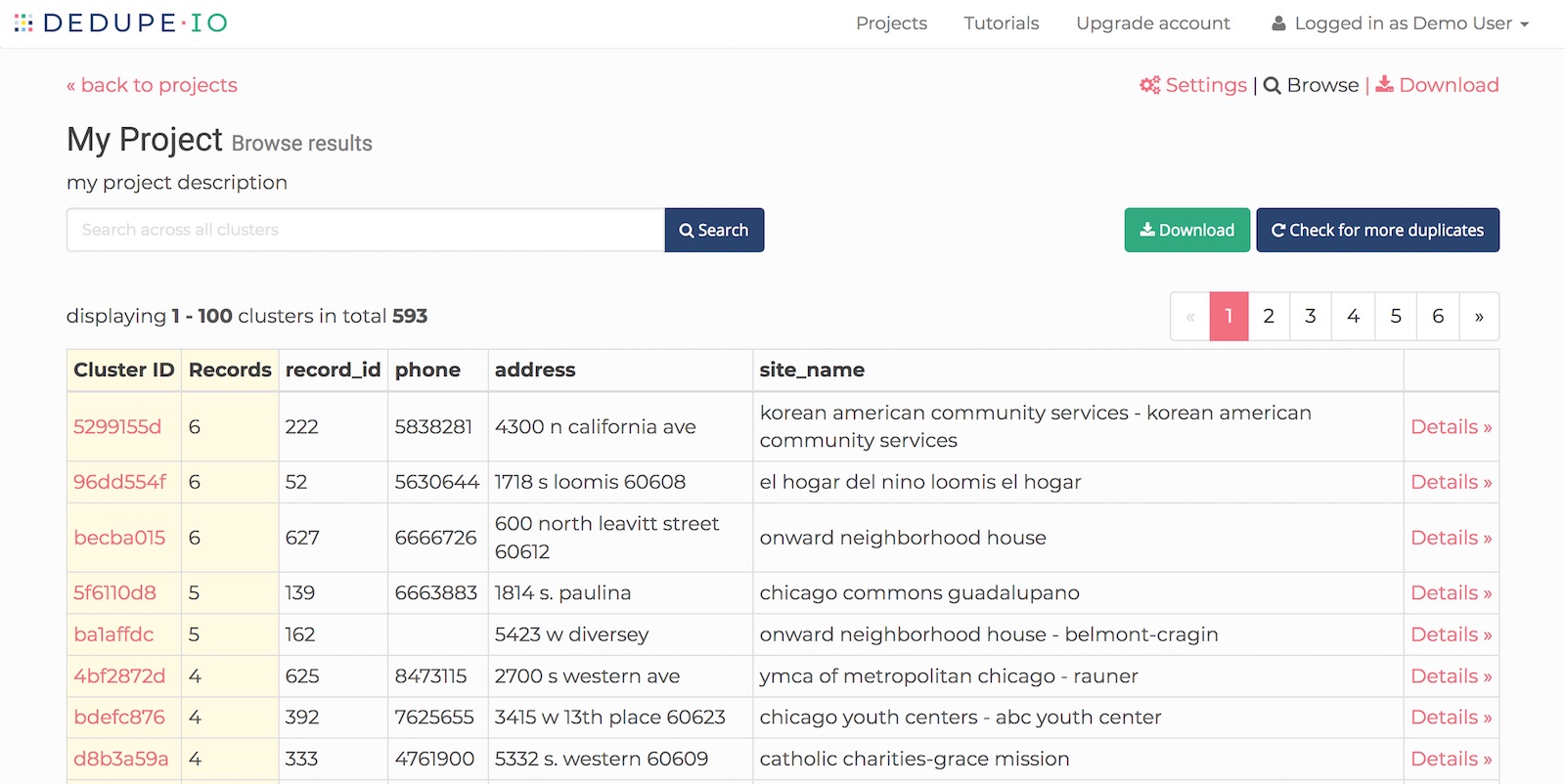
When Dedupe.io finishes processing, you’ll have the ability to browse your data. Click the ‘Browse clusters’ button on the home page, and you’ll be taken to the data browser:
Browse and cluster details
On the main browse page, your data is sorted by the clusters with the most records that are in them. Clicking on each one will open up a detail page for that cluster.
In it, you will see the Cluster ID, Number of records, Last edited and Edited by. We also show a Cluster short ID for easy reference.
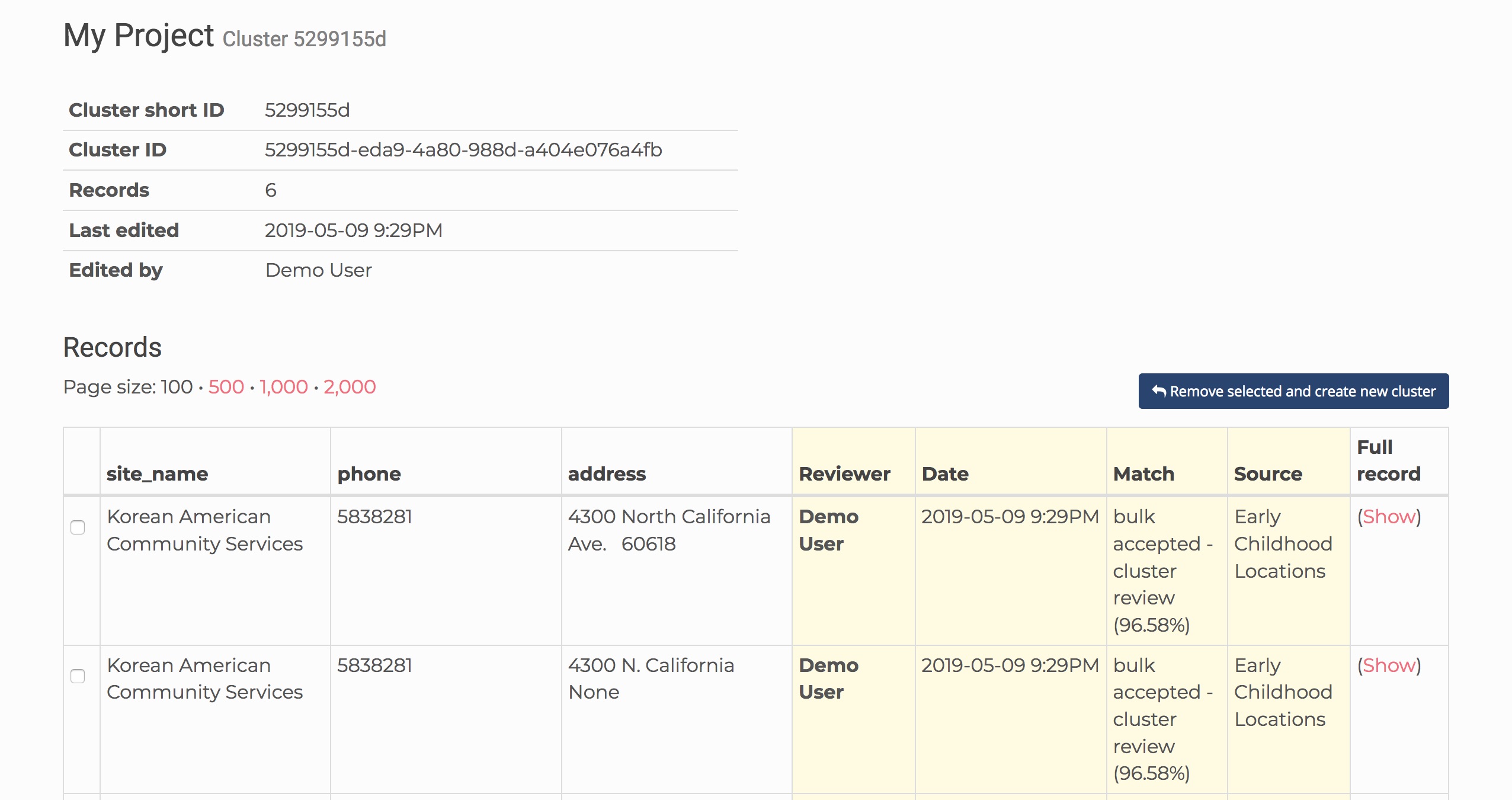
Below that, you will see an audit log of every record that was added to that cluster and why. You’ll see the fields you set in the ‘Select fields’ step, as well as some additional information:
Reviewer - The user or machine that made the decision for that record.
Date - The date of the action.
Match - Reason for the match. This could be from a user reviewing it manually, an exact match, or a high confidence match.
Source - When merging multiple datasets together, which dataset it belongs to.
You can also show the details for the full record, including the fields you didn’t tell Dedupe.io to match on.
Splitting clusters
If one or more records look like it doesn’t belong in this cluster, you can check the box next to it and click the ‘Remove and create new cluster with selected’ button. This will remove the record(s) from this cluster and put them all into a new cluster.
Search and merge clusters
On the main browse page, you can also search your data for specific keywords. Here’s a search for ‘mary crane’:
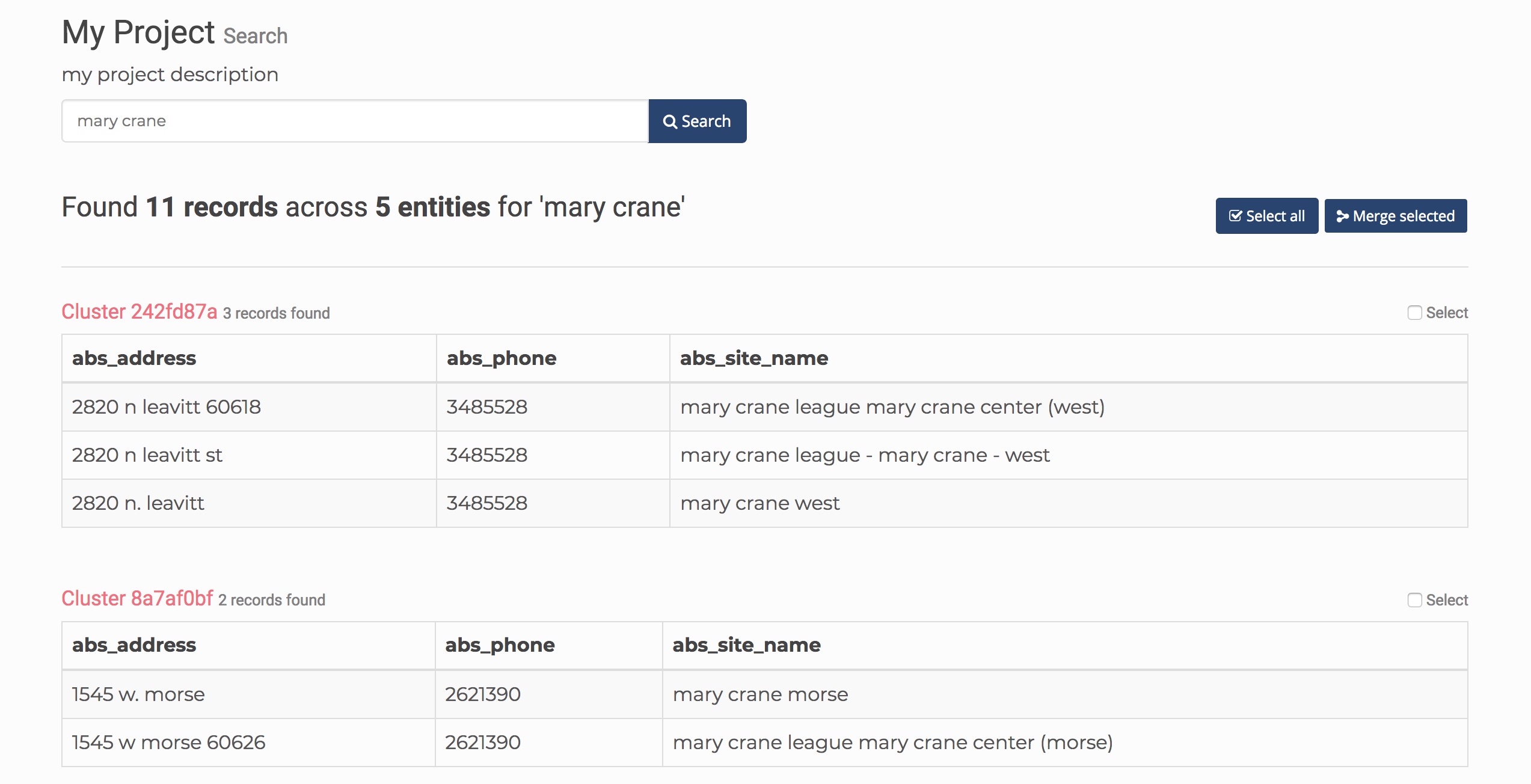
This is a good way to review your data and make sure special and ambiguous clusters are being handled.
If it looks like separate clusters should be merged, you can select them from the search results page and click the ‘Merge selected’ button. This will combine the selected clusters into a single cluster.
Check for more duplicates
If it looks like there are still duplicates in your results, you can click the ‘Check for more duplicates button’. This will trigger Dedupe.io to move your dataset back to the last ‘Polish clusters’ step and search for more potential clusters to merge.
Note: Incomplete and multi-spreadsheet tasks cannot check for more duplicates. Multi-spreadsheet tasks will be supported soon.
If your results look good, you can go to the downloads page and download the results of Dedupe.io as a comma separated values (CSV) file. On this page, we also allow you to download all of your training data and variable definitions.
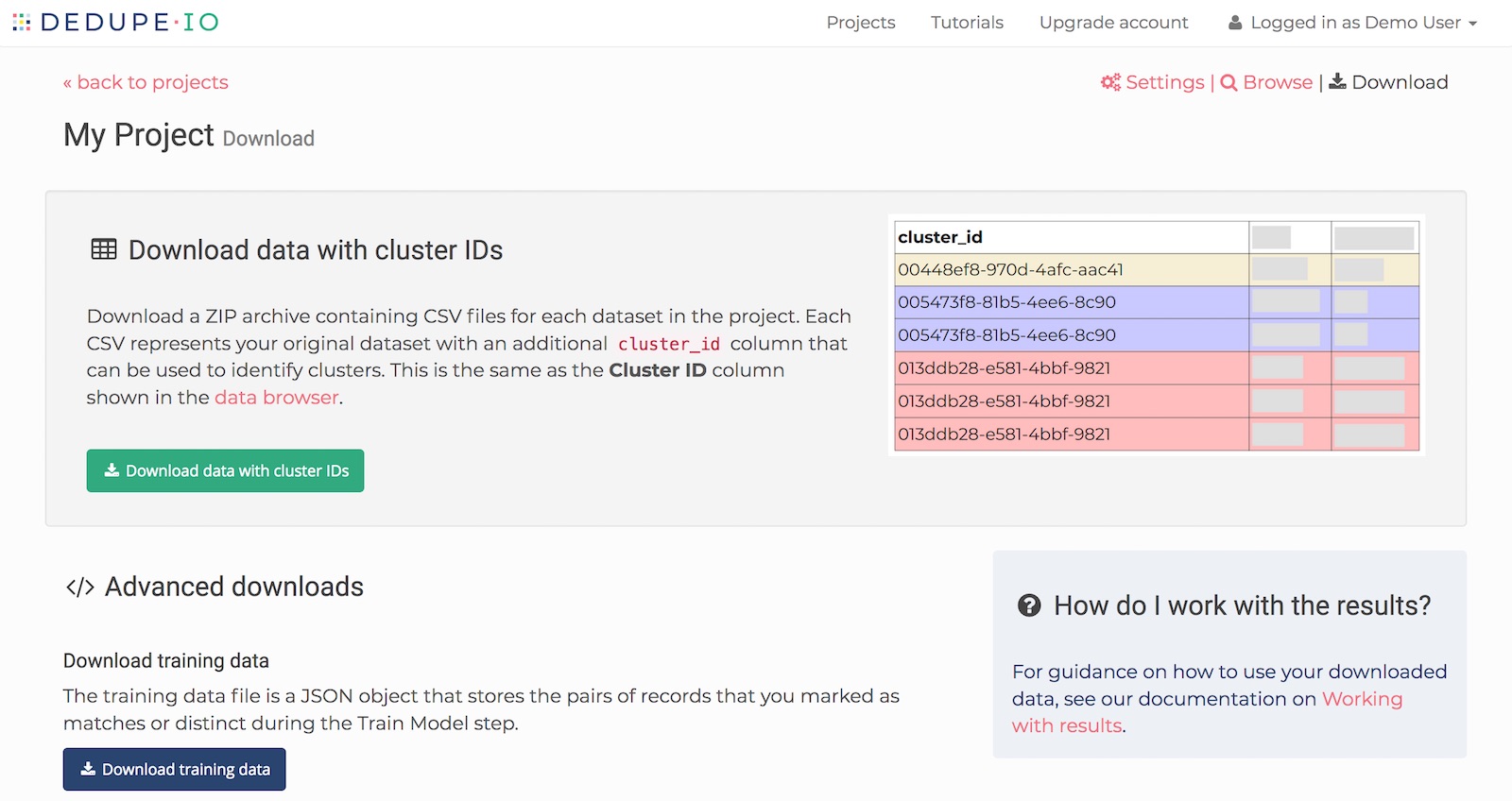
Download data with cluster IDs
When you download your data, it will contain original uploaded data with an additional ‘cluster_id’ column added. This is the same Cluster ID shown in the data browser.
From here, you can open up your data in Excel or load it into a program to start processing your data with the new unique cluster ID. Learn more about working with the results of Dedupe.io.
The settings page, linked to at the top of every step of the process, gives you an overview and some controls over your Dedupe.io session.
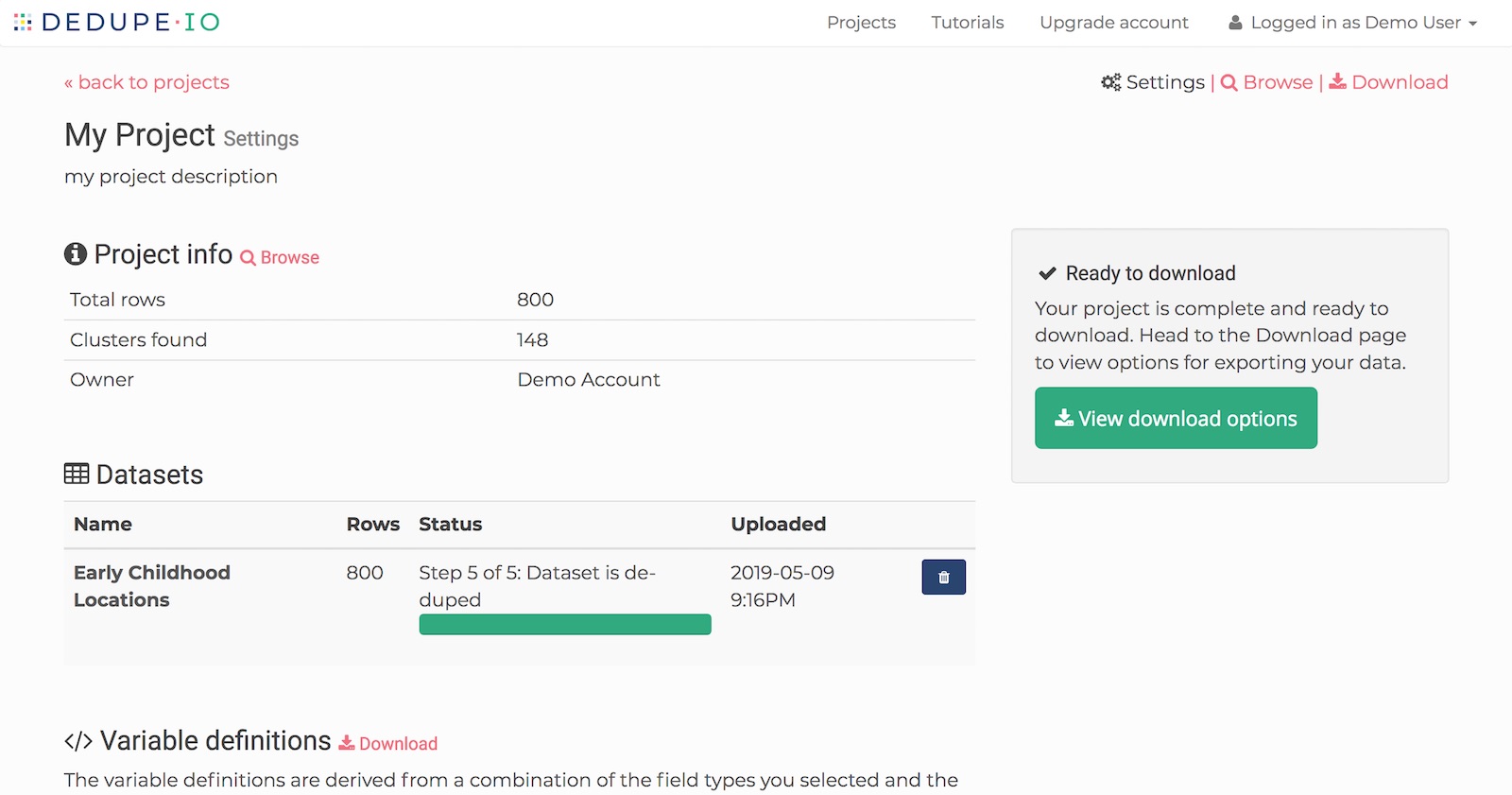
Here’s a rundown:
Project info - Shows the total number of rows imported, record clusters found and account owner of the project.
Datasets - A list of all datasets added to the project including what step each one is currently, date created and date updated. You can also delete individual datasets from your project here.
Variable definitions - The fields you have told Dedupe.io to pay attention to and how to compare them. You can download your data model for use with the dedupe library.
Danger zone
Delete project - This deletes your session and all the data you uploaded. Warning: this can not be undone!
Check for more duplicates After you’ve finished de-duplicating your data, you can have Dedupe.io try and find additional duplicates with a lower threshold. The threshold determines how to define clusters: a higher threshold makes several small clusters, and a lower threshold makes fewer large clusters. If you want Dedupe.io to be more aggressive in finding duplicates, set this number lower.
Advanced settings