Dedupe.io was shut down Jan 31, 2023.
The Dedupe.io team has decided to dedicate our focus to our consulting practice at DataMade and work on projects more aligned with our mission to support our clients in working toward democracy, justice, and equity.
We are continuing our consulting practice around the open source dedupe library and would be happy to consult with you on setting up a solution based on it. Contact us to get started >
Dedupe.io can compare your fields in different ways depending on the makeup of the data.
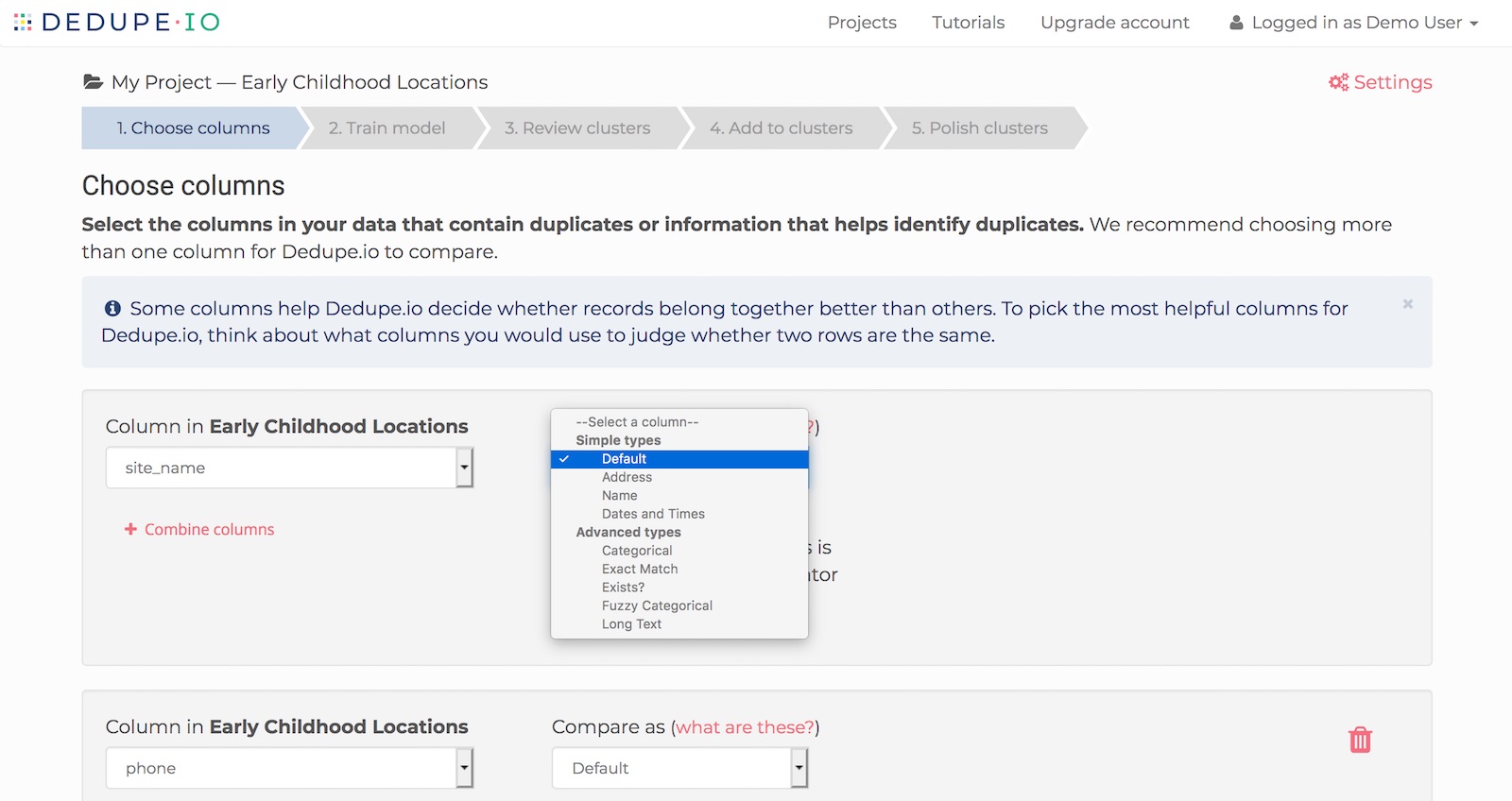
The 'Define fields' page on Dedupe.io
These are the most commonly used comparators. They will handle most types of data you want to compare like names, addresses and dates. If you're not sure what one to pick, Default is always a good option.
| Comparator | Description | Example |
|---|---|---|
| Default | Default comparator. Fields will be compared based on how similar they are to each other, character by character. This is the most versitile and commonly used comparator and will work best on most fields. |
atty title guaranty fund
vs attorneys' title guarantee fund, inc.
|
| Address | Splits addresses into separate components using usaddress. Works best on addresses in the United States. |
1 S. Wacker Dr Chicago
vs One South Wacker Chicago, IL
|
| Name | Splits names into separate components using probablepeople. Good for western person names, company names and households. |
Mr George 'Gob' Bluth II
vs George Bluth Jr
|
| Dates and Times | Compares calendar dates and times of day using the python dateutil library. Good for dates of birth or event dates. |
2017-07-25
vs Tuesday, July 25th 2017
|
| Positive Number | For comparing positive, non-zero numbers based on how close their values are. This is useful for comparing values like price, age, or count. Non-numeric characters will be ignored. If a value is 0 or negative, it will also be ignored. |
$199.25
vs 190
|
If you know more about the structure of your data, you can use these advanced comparators to create custom rules that will improve the accuracy of your de-duplication results.
| Comparator | Description | Examples |
|---|---|---|
| Categorical | Used for comparing keywords or categories with a small number of options (5 or less). |
red vs
green
|
| Exact Match | Checks to see if the fields exactly match or not. Good for cleaned and consistent data. |
Chicago, IL vs Chicago, IL
|
| Exists? | Measures whether both, one, or neither of the fields are defined. Good for sparsely populated data (when presence is significant). |
ABC vs
|
| Fuzzy Categorical | Used for comparing keywords or categories with a large number of options (more than 5). This is useful for fields like occupation or employer. |
Attorney vs Lawyer
|
| Long Text | Compares entire words. Useful for longer text fields. Good for product descriptions or article abstracts. |
The quick brown fox jumped over the lazy dog. vs The slow brown squirrel hopped over the sleeping dog.
|
For particularly messy datasets, we can improve the results of Dedupe.io by building custom parsers fine-tuned for your data. Custom parsers enable smarter matches by breaking up semi-structured text into separate fields for better comparisons.
For more information, contact us at info@datamade.us