Dedupe.io was shut down Jan 31, 2023.
The Dedupe.io team has decided to dedicate our focus to our consulting practice at DataMade and work on projects more aligned with our mission to support our clients in working toward democracy, justice, and equity.
We are continuing our consulting practice around the open source dedupe library and would be happy to consult with you on setting up a solution based on it. Contact us to get started >
Frequently asked questions (and answers) from Dedupe.io users.
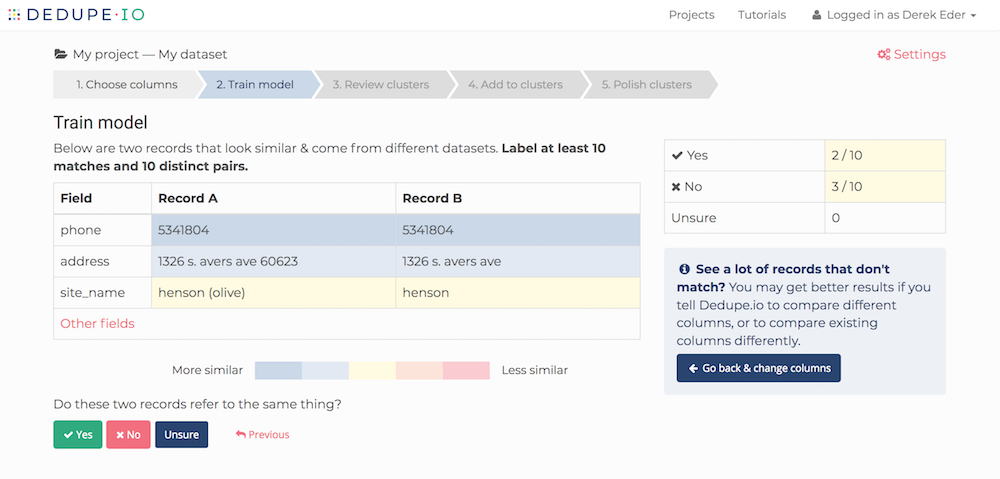
A good rule of thumb to follow when picking fields to compare is to select the same fields you would use if you were looking at two records yourself.
For data about places, organizations, or people, fields like name, address, phone number and category are great to include.
For data about products, the product name, SKU, size and price may be useful for you.
Determining what fields to compare can be tricky and often times require some trial and error to get right. For this, we give you the option to start training and go back a step if the training looks incorrect.
The Dedupe.io team is also available to consult with you on setting up your Dedupe.io projects.
On the Projects home page, each project you have has a settings page. On the project Settings page, you can delete the project or any of the datasets associated with it.
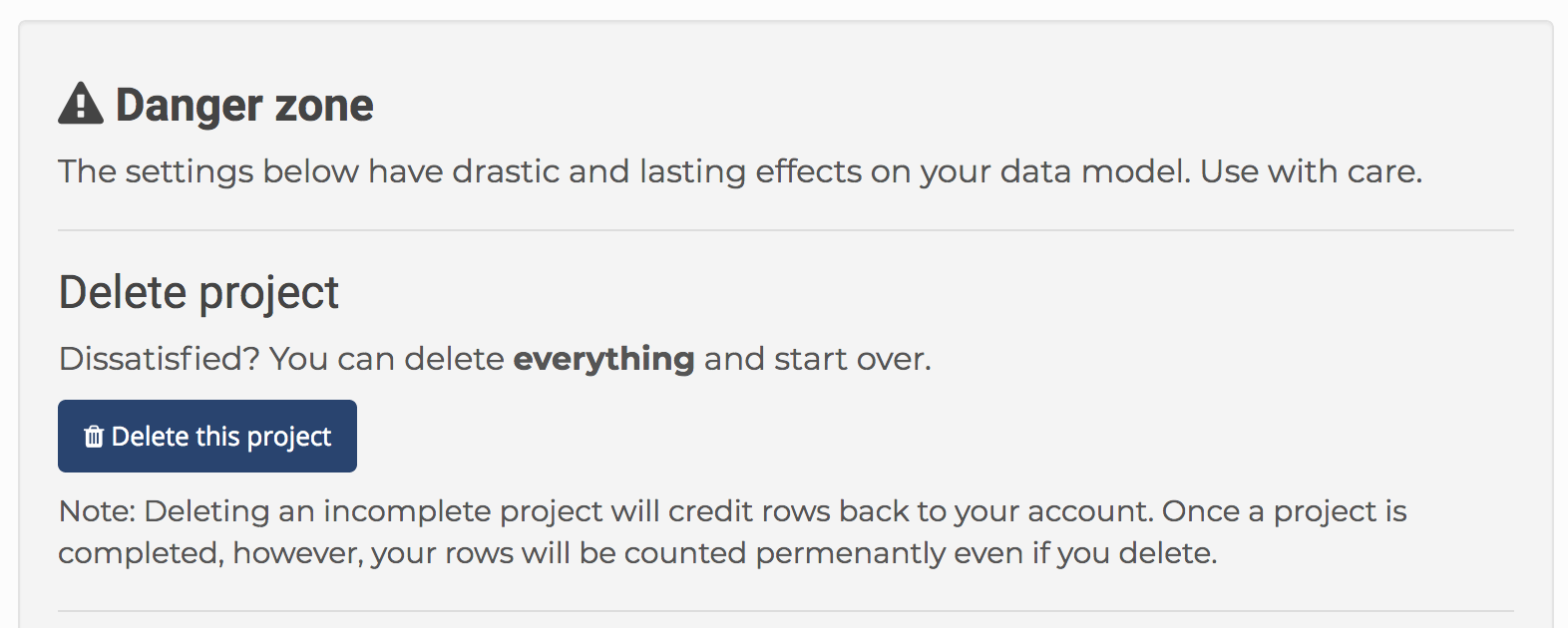
Deleting a project or dataset is permanent and cannot be undone. It will erase the data from the Dedupe.io system.
Training data from one project can be reused in another one if the fields you select are named exactly the same. This can be useful for saving time on similar projects.
Here are the steps for reusing training data:
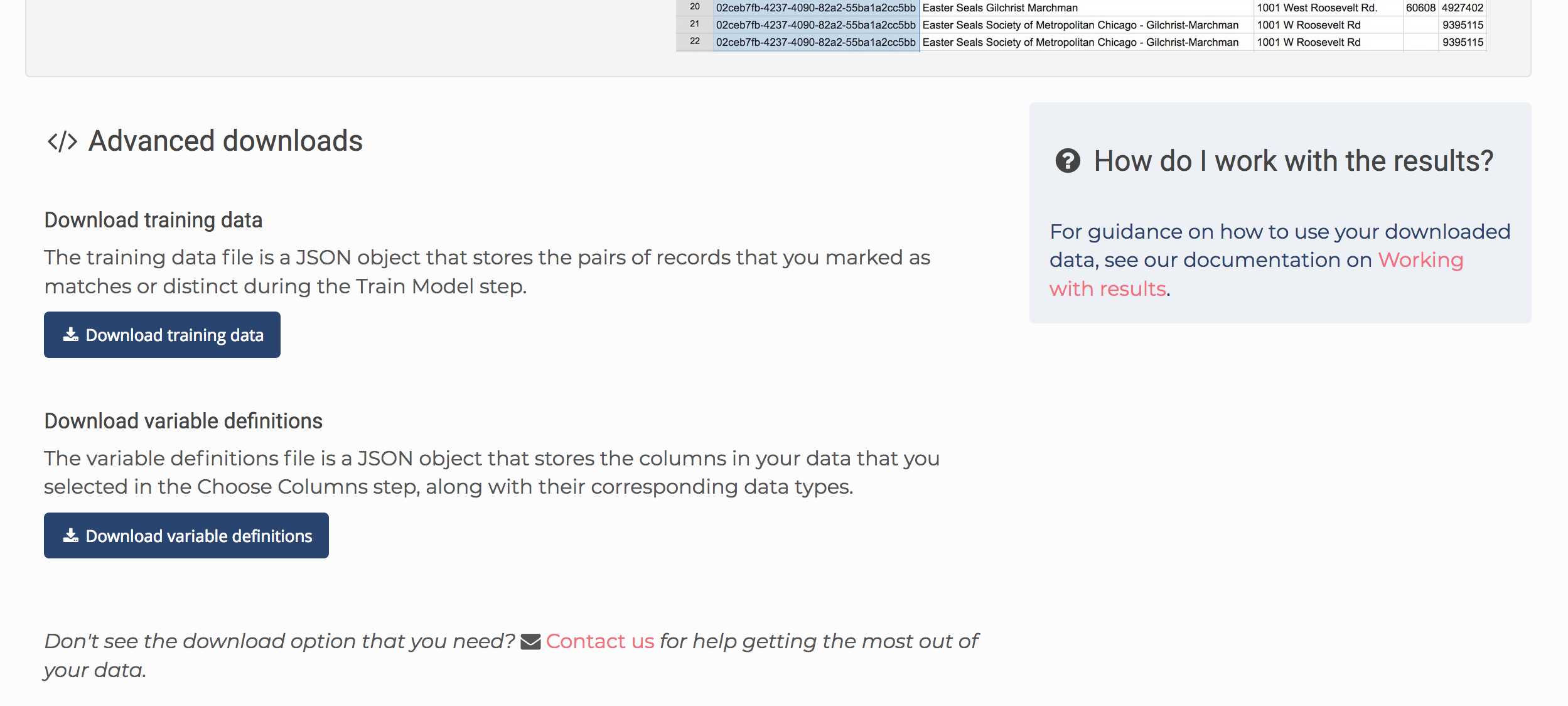
1) Navigate to the Download page for your project and click ‘Download your training data’ under Advanced downloads. The training data represents all the decisions you made during the Train model step, as well as the Review clusters, Add to clusters and Polish clusters steps.
2) Start a new project and upload your data file. On the ‘Choose columns’ step, pick the exact same columns you used in the first project. These must be spelled exactly the same for the training data to be reused. When you’re done adding columns, click the Next button.
3) Before you begin training again, navigate to the Settings page for your new project. At the very bottom is an area where you can choose a training file to upload. Choose your training data file from your first project and upload it.
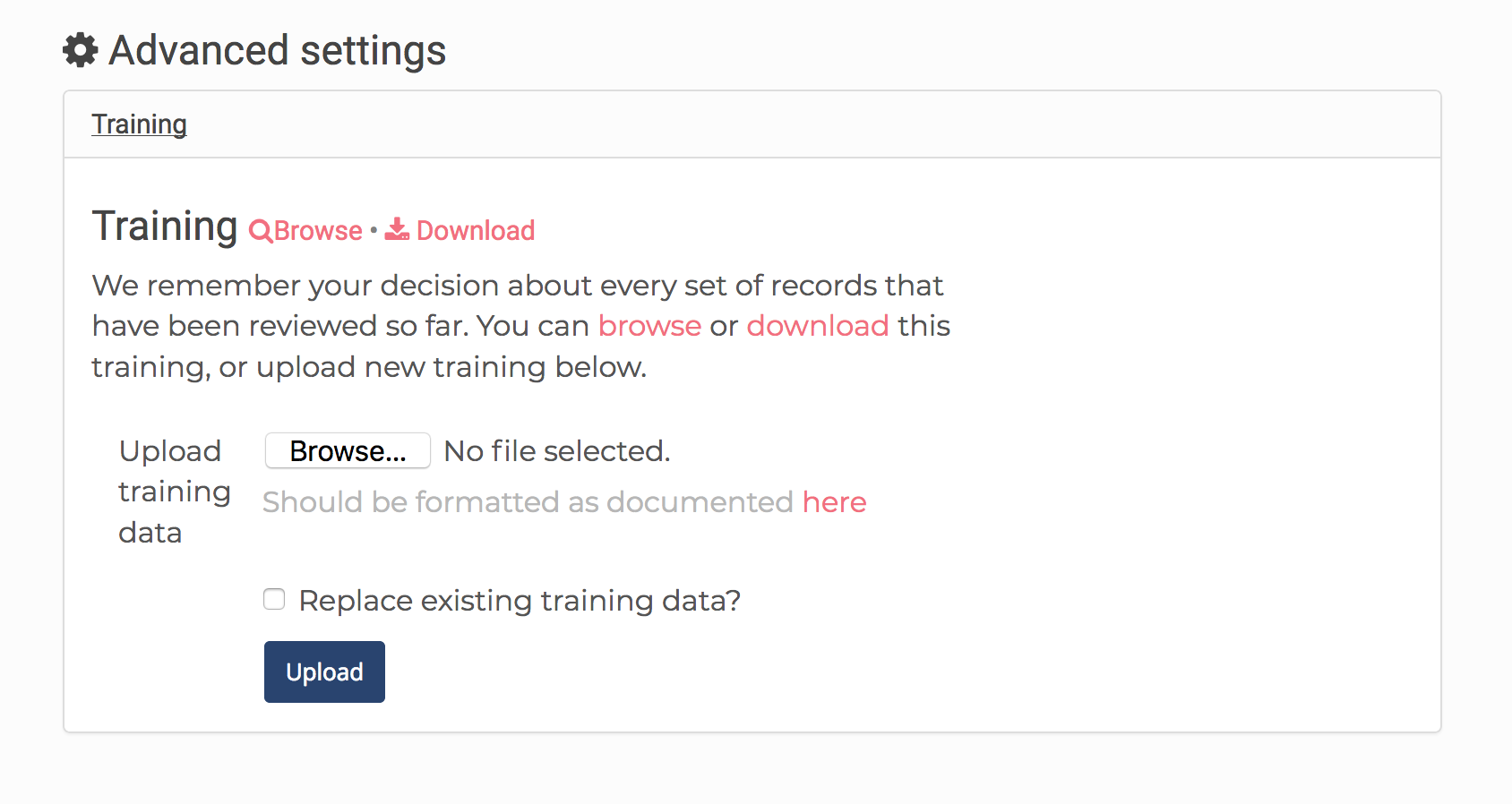
4) Then, back at the top of the Settings page, click on Next step: Train model. You should see that you have additional Yes/No answers loaded in. You can continue training if you’d like, or move on to the next step by clicking the ‘Next’ button.
Note, you will likely have a lot more training than you expect. That is because the Review clusters, Add to clusters and Polish clusters steps also create training data.
See our documentation on working with Dedupe.io’s results.
Good question! We provide detailed documentation on our approach to deduplication here.
You can import a file of these file types:
Spreadsheets (.xls, .xslx)
Comma-separated text (.csv)
The file must contain one row for every record, with the first row indicating the name of each column.
Read more on formatting files for upload.
On the training step, we require you to answer a minimum of 10 ‘yes’ and 10 ‘no’ pairs of records. This minimum was determined to be a good floor for most projects, as Dedupe.io needs a decent amount of training to create an accurate data model.
That being said, we do give you the option of providing as much training as you want. For datasets with few fields to compare or particularly messy or ambiguous data, we recommend more training. Each pair of records you mark provides useful information to Dedupe.io, but each pair you mark provides less and less learning to Dedupe.io.
Even for messy and difficult datasets, it is rarely necessary to provide more than 50 ‘yes’ and 50 ‘no’ training pairs.
Our privacy policy states:
“We neither rent nor sell any of the data you provide to us to anyone. We will not allow third parties to access your data without your signed consent. Dedupe.io LLC will not access your data except for the purposes of debugging and improving the service.”
Furthermore, as of July 2019, Dedupe.io has been certified compliant with the Family Educational Rights and Privacy Act (FERPA). Being FERPA compliant means that our data privacy systems are strong enough to handle sensitive student data, but more broadly, it also means that a third-party security team has audited our application architecture and verified that we take data privacy seriously.
You can delete a project or a dataset from a project at any time from the project Settings page.
If the dataset is on any step before being de-duplicated, or if you indicated that it contained no duplicates when you uploaded it, deleting it will credit all the rows for that dataset back to your account.
If the dataset has been de-duplicated, the rows will be counted permanently and deleting it will not credit any rows back to you.