Dedupe.io was shut down Jan 31, 2023.
The Dedupe.io team has decided to dedicate our focus to our consulting practice at DataMade and work on projects more aligned with our mission to support our clients in working toward democracy, justice, and equity.
We are continuing our consulting practice around the open source dedupe library and would be happy to consult with you on setting up a solution based on it. Contact us to get started >
In this tutorial, we will go over how to merge or find matches across multiple datasets using Dedupe.io.
Dedupe.io takes the approach of starting with one dataset, optionally de-duplicating it, and then linking additional datasets to it, one at a time.
Dedupe.io has two modes of working with multiple datasets:
Merge: Your datasets will be combined together into one unified set of clusters. Adding additional datasets will add to those clusters.
Find matches: Upload one dataset to check for matches against. For each dataset you add, Dedupe.io will find what records match against your original dataset.
In this example, I am going to link together two lists of restaurants, each with the name, address, city and type of cusine.
If you'd like to follow along, you can use our example data for this tutorial:
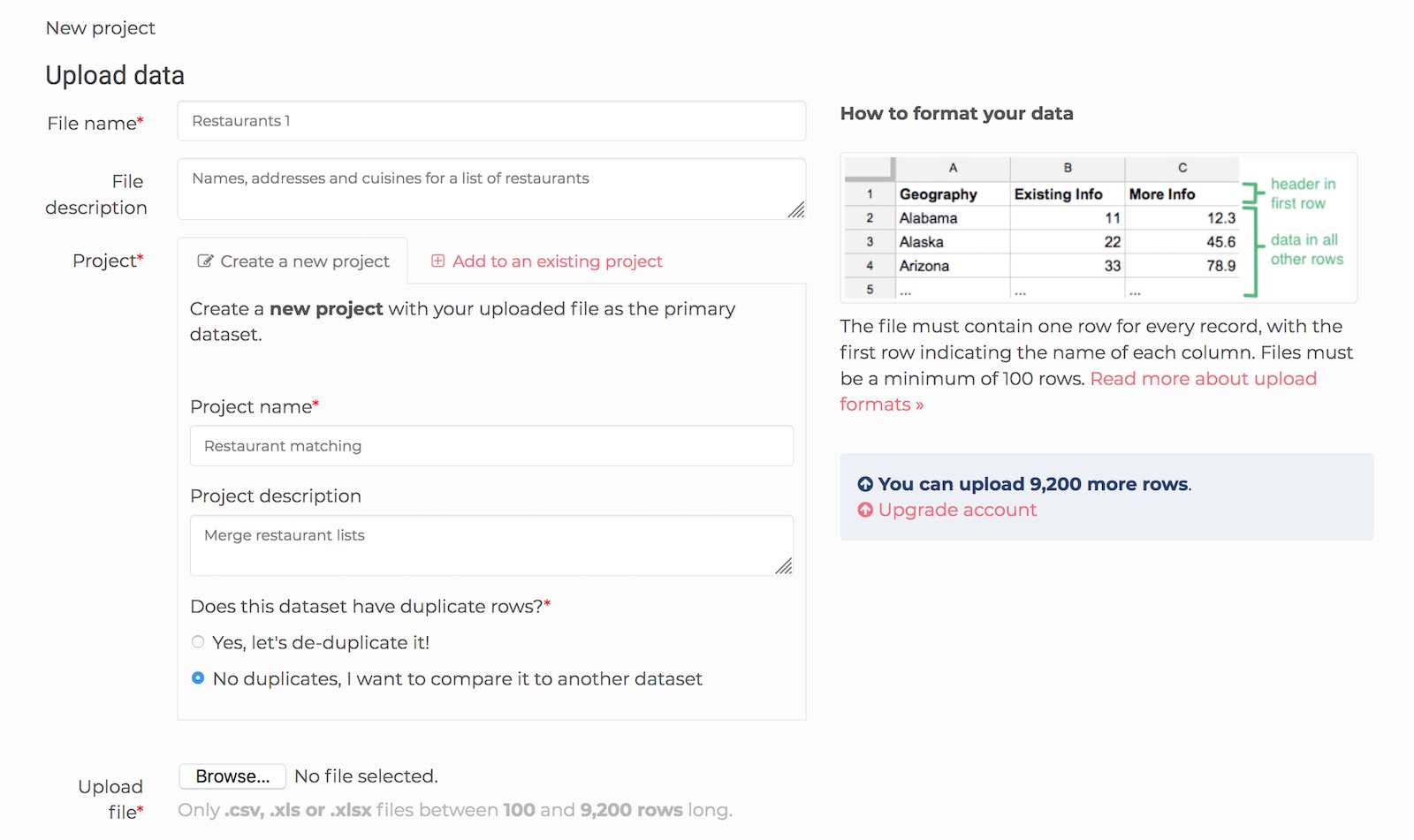
To start a data linking session, start by uploading a dataset you want to link by clicking on the ‘Upload a new dataset’ button. You’ll be taken to the Upload data page.
Uploading an already de-duplicated file
Here, you can name your dataset, provide and optional description for it. You will also be prompted to Create a new project or Add to an existing project.
Projects are used for grouping multiple datasets together for matching. We’re starting a new project here, so I’ll fill in the project name and project description.
Uploading de-duplicated data
Dedupe.io supports uploading datasets that are already de-duplicated (one row for each unique record). If this is the case, you can select the ‘No duplicates, I want to compare it to another dataset’ radio button. Checking this will skip all the Dedupe.io steps and mark your dataset as de-duplicated in the system.
In this example, I am starting a new project and selecting the ‘No duplicates, I want to compare it to another dataset’ radio button.
When it’s done, I will upload the second dataset: Restaurants 2. For this dataset, I am going to Add to an existing project and select my Restaurant Matching project from the list.
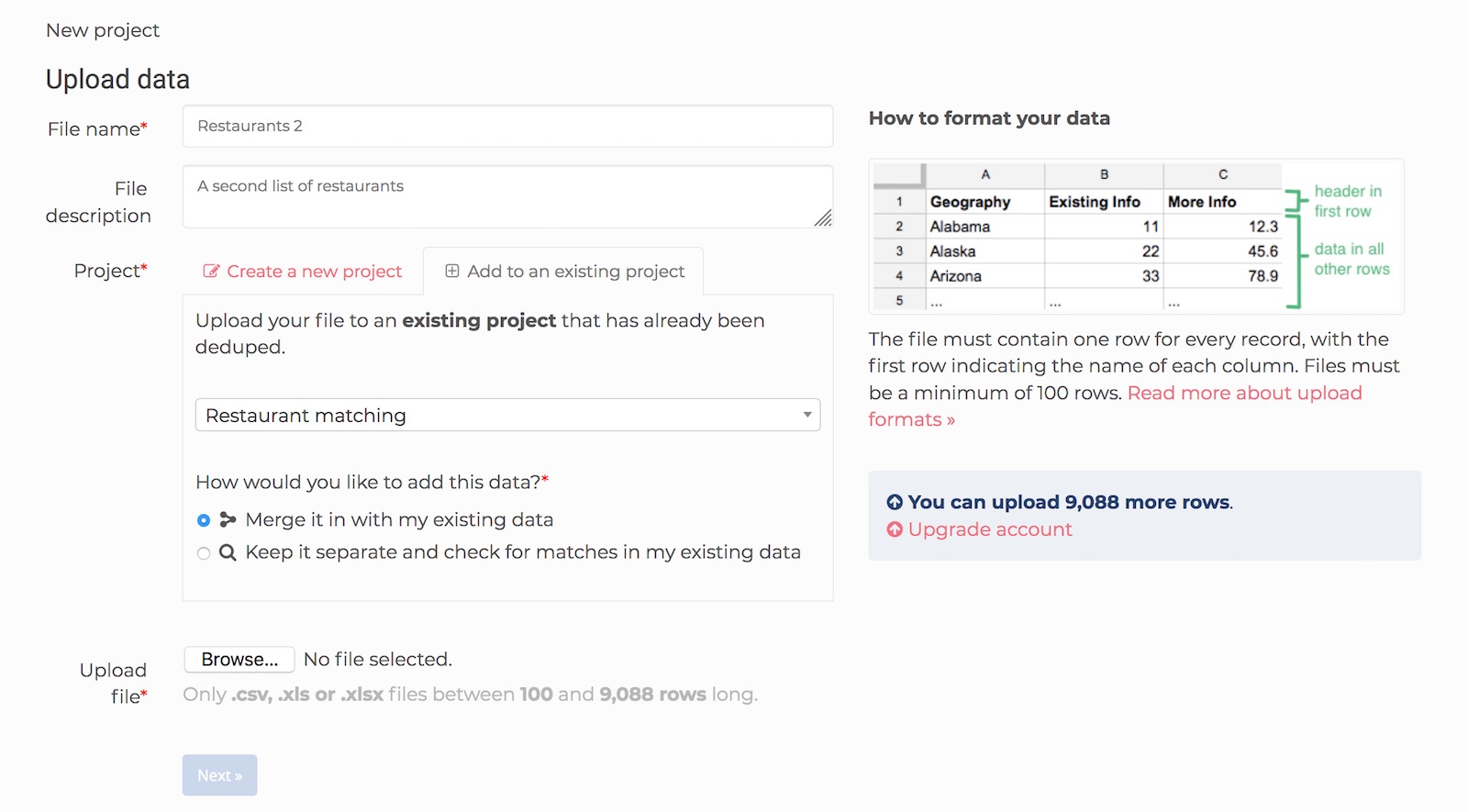
Adding Restaurants 2 to the Restaurant Matching project
Once I’ve uploaded the data and it has been processed, we’ll move on to the next step.
Next, we will identify the fields in each dataset that we want Dedupe.io to pay attention to for finding duplicates. You’ll be shown a drop down list of column names to pick from.
Next to that, you will pick from Compare as to tell Dedupe.io how to compare values in that column. The Default comparator will compare based on how similar each field is, character by character. Address will automatically split address and into separate components making them much easier to compare. Name will do the same for person and company names.
Dedupe.io has several other kinds of comparators, which you can read about on the field comparators page.
In the case of my restaurants data, I want to link on name, address, city and cuisine.
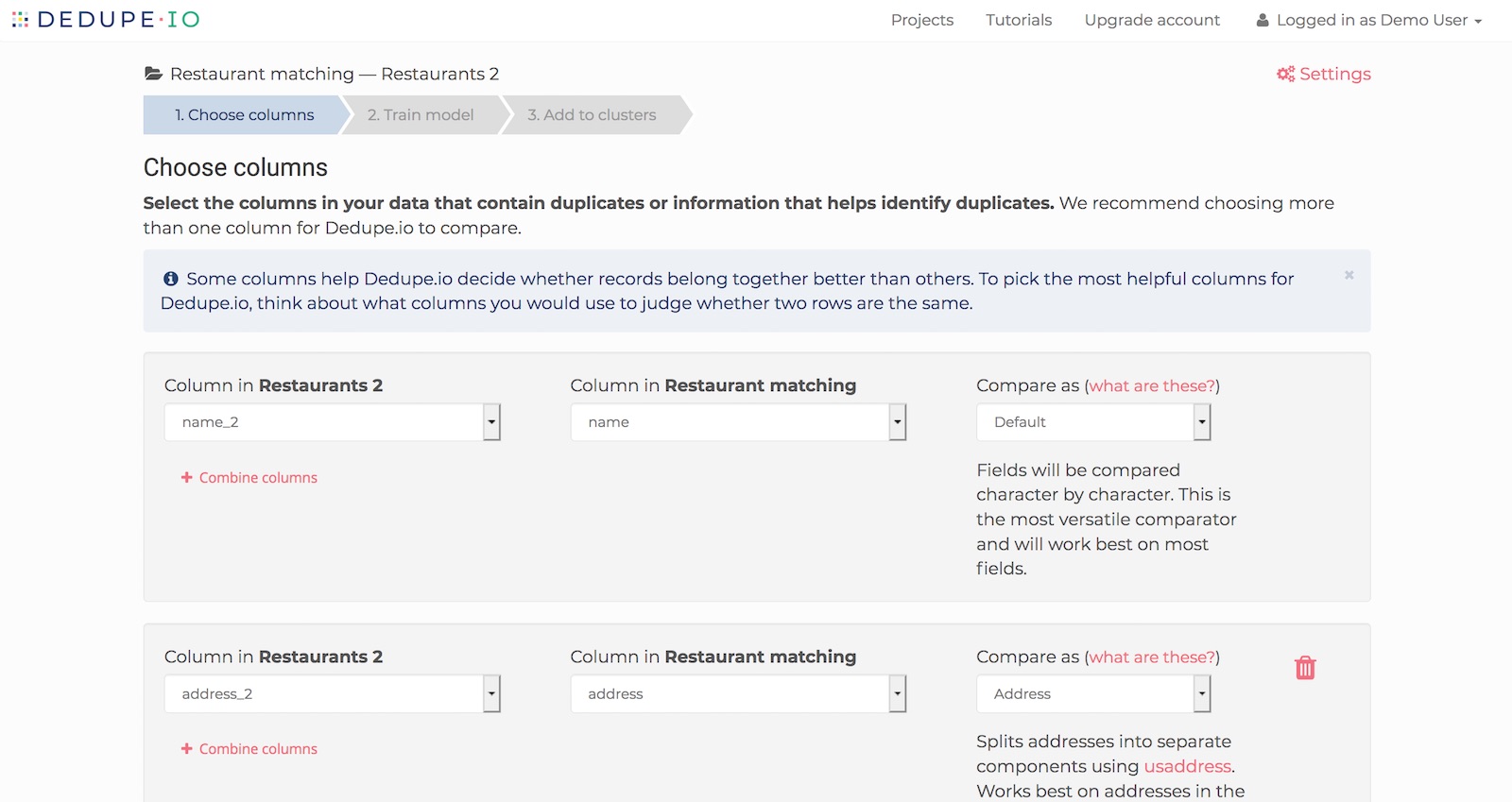
Aligning fields to compare
We don’t need it here, but Dedupe.io can combine multiple fields together and treat them as one thing. This is especially useful for address and name fields where their parts are spread across multiple fields.
Next, dedupe.io will take a sample from each of your datasets and pick two random records for you to review.
For this pair of records, Dedupe.io asks us, ‘Do these records refer to the same thing?’ We will answer ‘Yes’, ‘No’, or ‘Unsure’. Once we mark these records, Dedupe.io will find another pair for us to review and we’ll repeat the process.
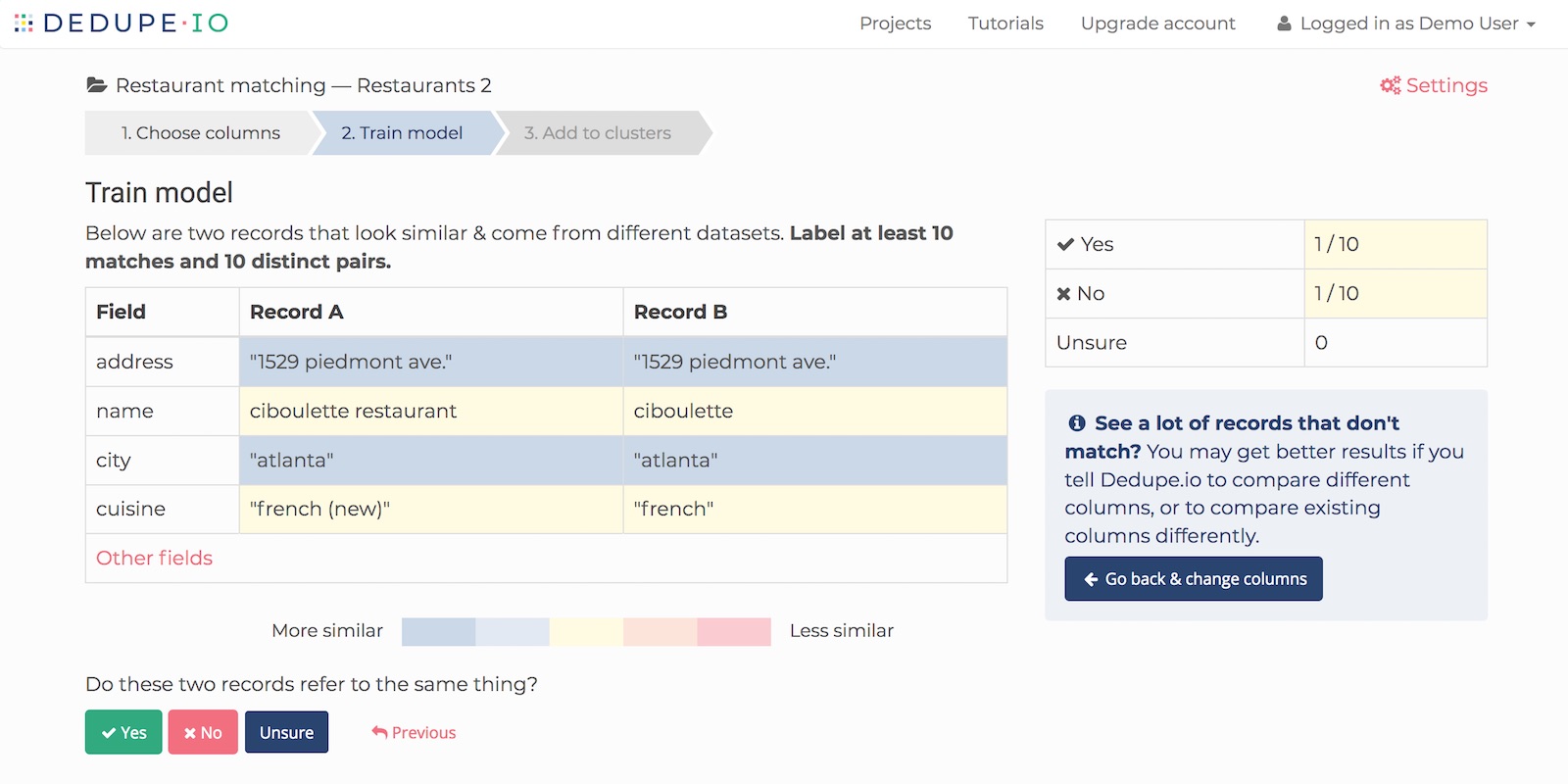
Training Dedupe.io
Dedupe.io uses these responses to refine its understanding of your data. The more training you provide, the better the linking results will be. At a minimum, we need 10 positive and 10 negative responses to proceed.
You are, however, welcome to provide as much training as you’d like. Just know that Dedupe.io will learn a little less for each additional training pair you mark. Stopping at 50 yes and 50 no responses would be more than enough.
Once you’re done training and click the ‘Next’ button, Dedupe.io will take some time to apply your training to the rest of your data. This can take several minutes for datasets under 100,000 rows to several hours for datasets with millions of rows.
Now that it has a good idea of the clusters that are in your data, it is looking through all the individual records that have not yet been added to a cluster.
When it is finished, you will be able to continue on to the next step. Here, we will review these records and match them to one or more clusters.
In this example, we have an unmatched record in yellow and two clusters that look like good matches. We’ll keep the checkbox next to each cluster checked and click the ‘Match record to cluster(s)’ button.
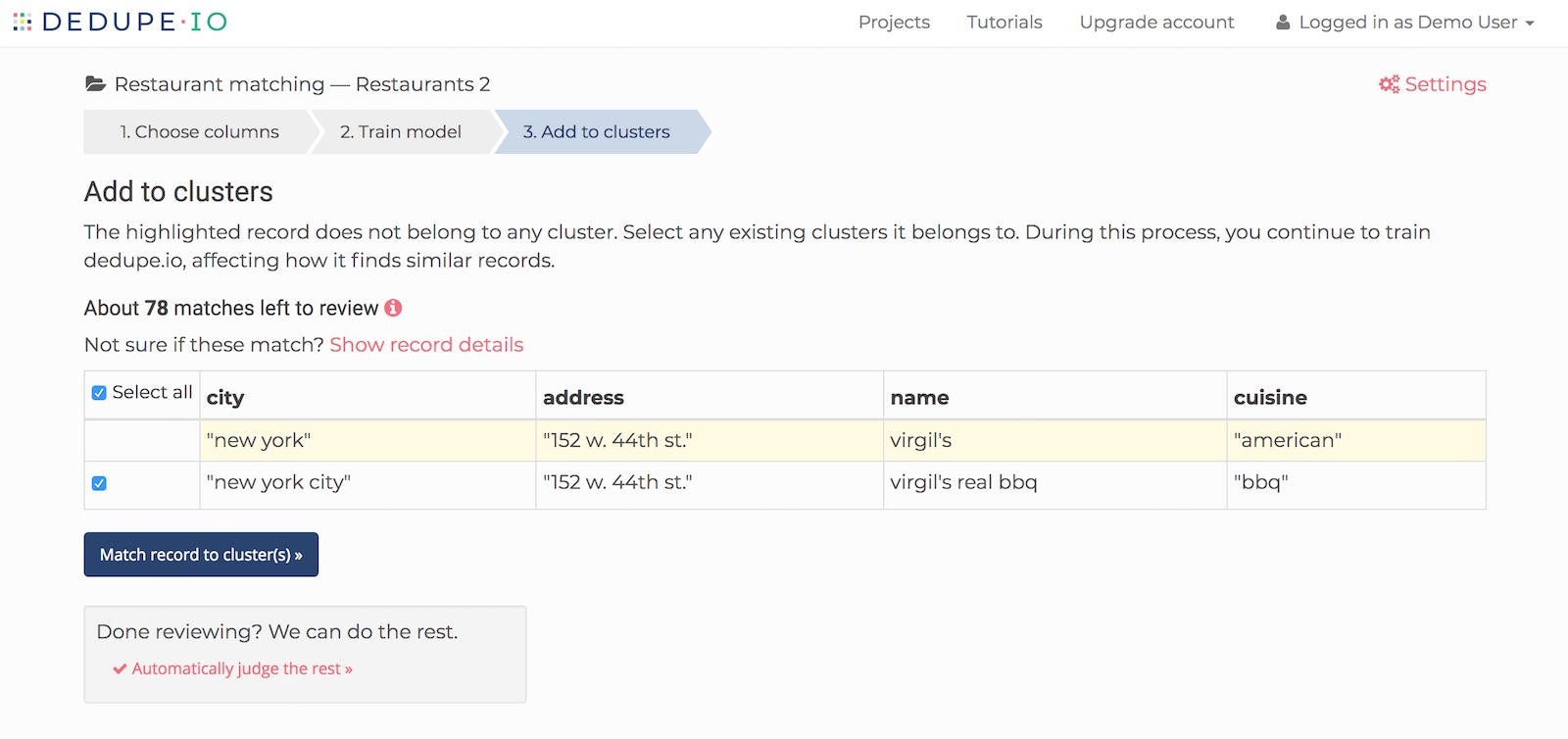
Matching records
Automatically accepting the rest
After reviewing each record, we’ll be shown another one until we’ve gone through the entire queue. We have the option if we’re confident enough, to ‘Automatically judge the rest’. Clicking this will have Dedupe.io judge the rest of the records automatically and skip us ahead to the next and final step.
Warning: take caution when automatically judging too many records. The records Dedupe.io is asking you to match here are the records that are often the most ambiguous. We recommend reviewing as many of these records as possible for the best results.
When Dedupe.io finishes processing, you’ll have the ability to browse your data. For additional instructions, read the section on browsing your results in Getting started with Dedupe.io tutorial.
When doing a merge operation, the results will look similar to how they look when de-duplicating a single dataset:
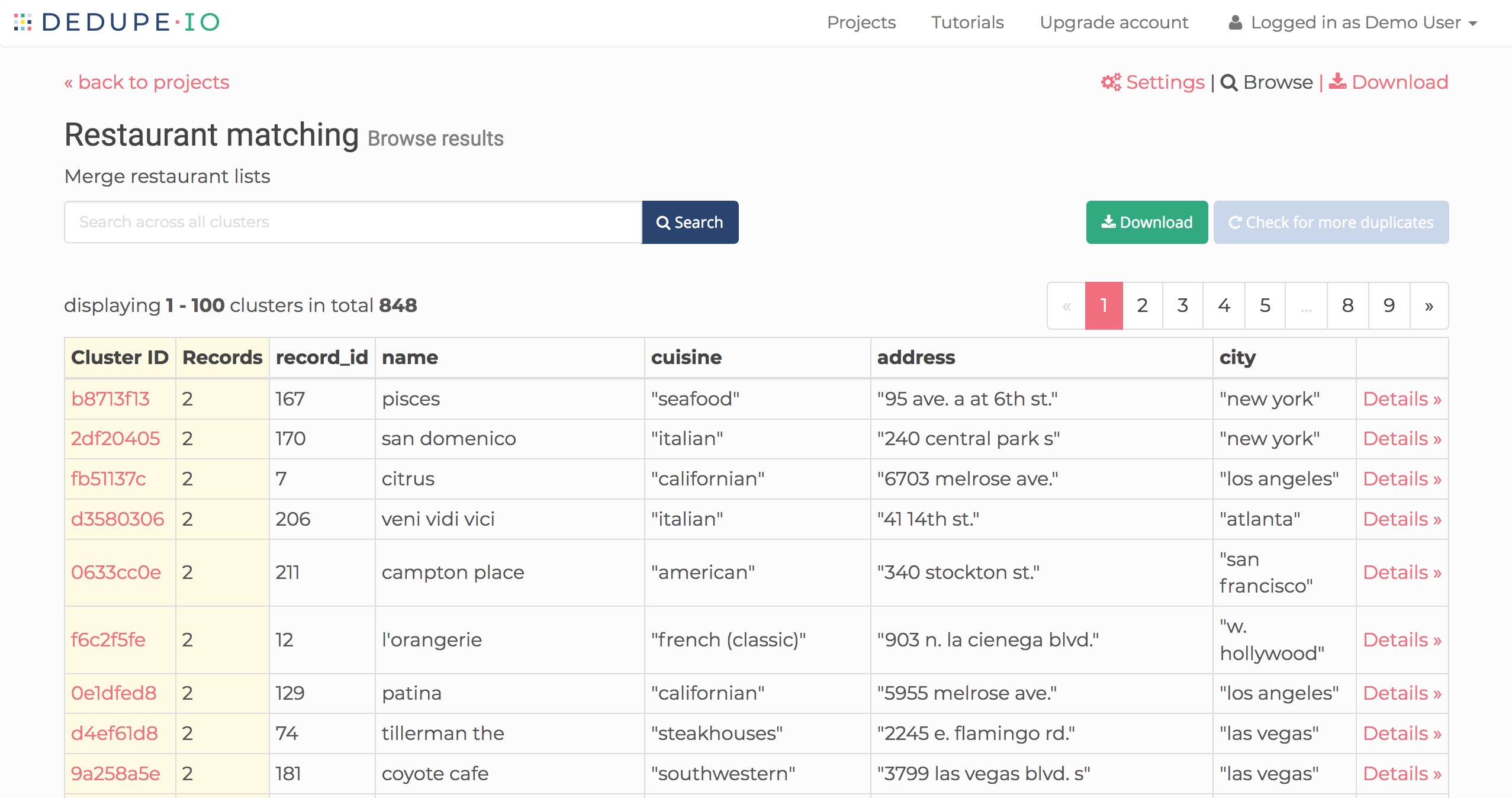
Merged results
If your results look good, you can download your data. When downloading the results for merge projects, we give you back all of your original data files in comma separated values (CSV) format. You can open this file up in your favorite spreadsheet software.
Data download
In the results file is your original data with an additional cluster_id column added. This is the same Cluster ID shown in the data browser. The cluster_id is a unique identifier - if a row in either spreadsheet has the same cluster_id, they belong in the same cluster.
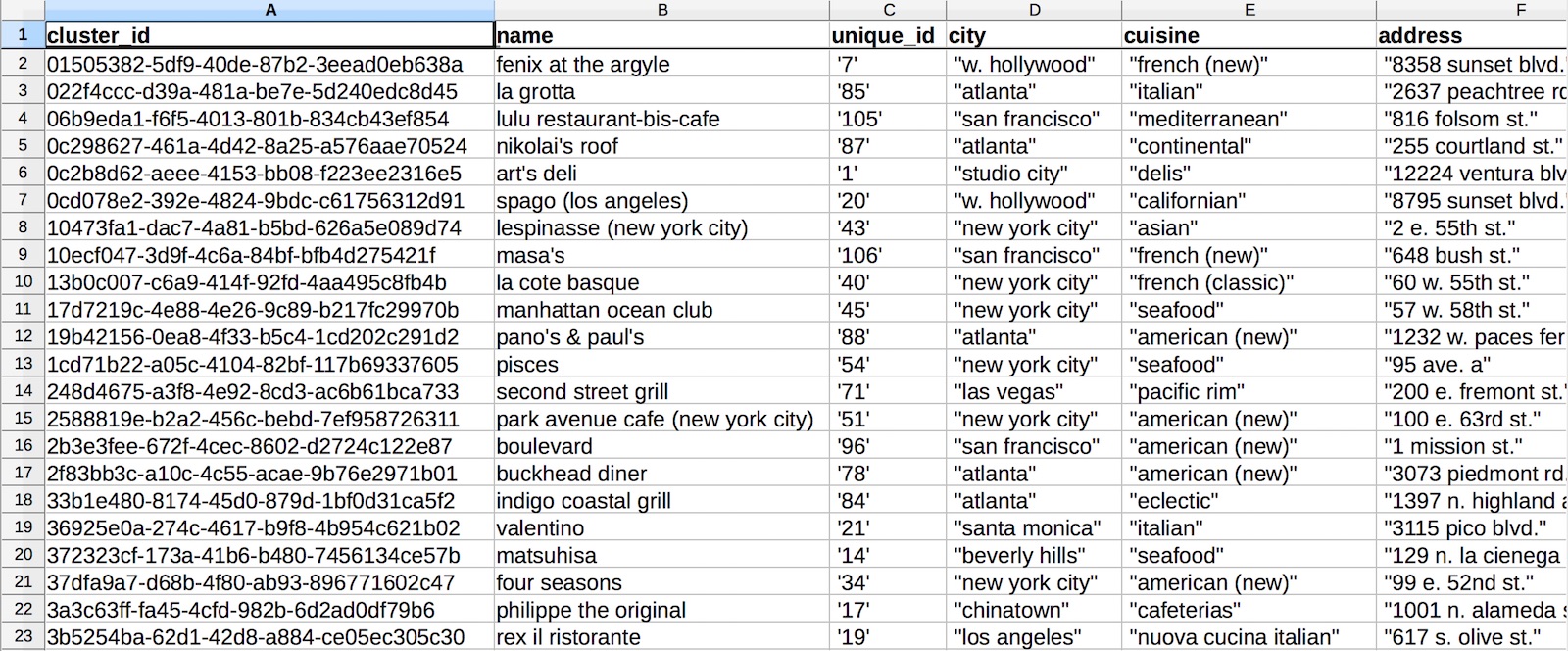
Downloaded merge results from Dedupe.io
When doing a find matches operation, the results will be shown in several tabs, one for each dataset you added to the project.
The first tab represents the records we’re matching against, which we call canonical. Each tab after that shows matches between a file and the canoncal dataset.
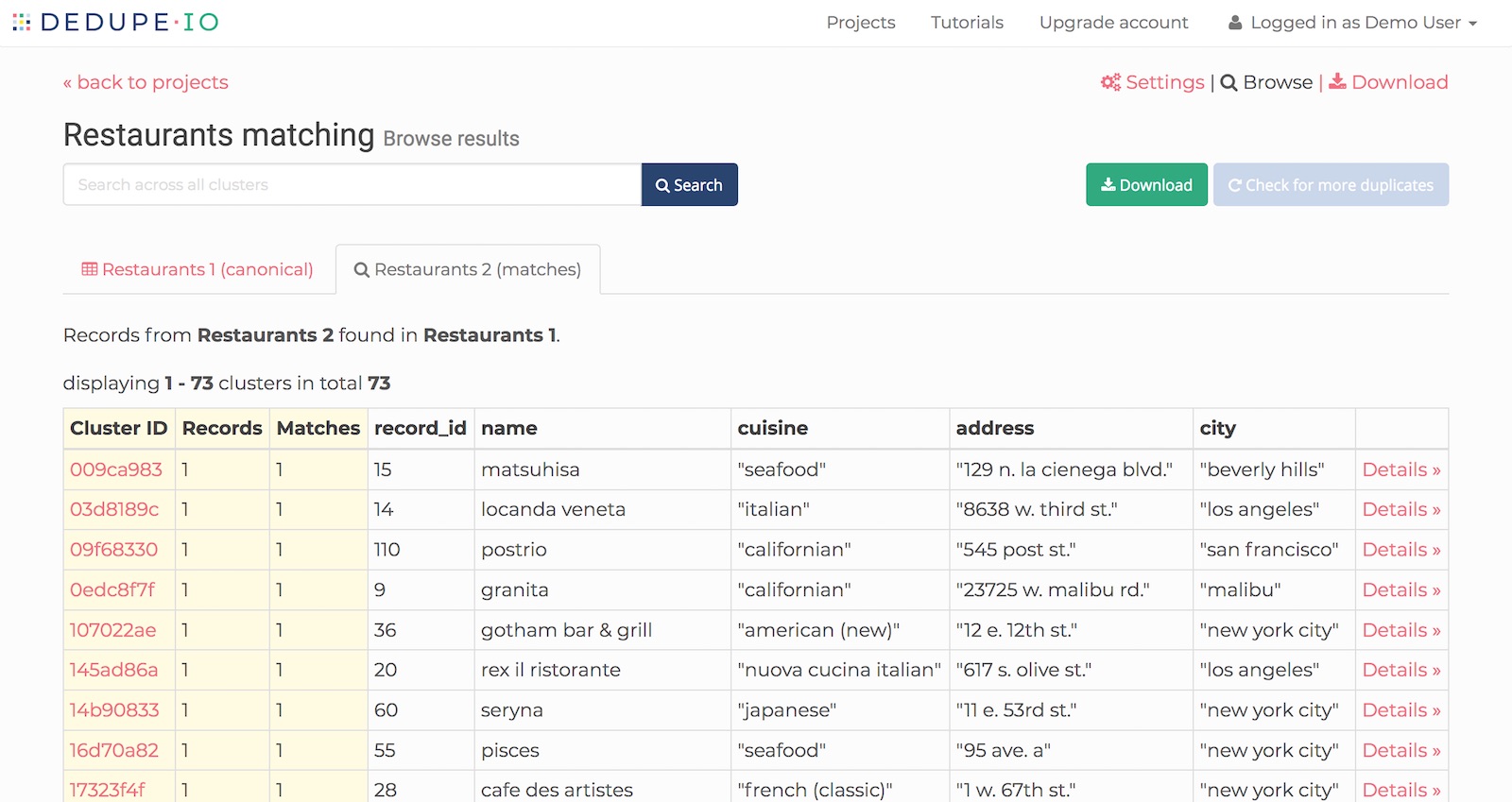
Find matches results
Data download
When downloading the results for matching projects, we give you back all of your original data files in comma separated values (CSV) format. You can open this file up in your favorite spreadsheet software.
The results file for your original data will have a cluster_id assigned to each row. For every dataset you matched against, every row that Dedupe.io finds as a match in your original data will be assigned a matching cluster_id. Rows that do not match will be left blank.

Downloaded match results from Dedupe.io